SEED | Co-Scientist:AI 假说进入实验循环 SEED | Co-Scientist turns hypotheses into experiments AI-assisted · reviewed
Google Cloud AI Research、Google DeepMind、Google Research 与合作者的 Juraj Gottweis、Pushmeet Kohli、Annalisa Pawlosky、Alan Karthikesalingam、Vivek Natarajan 团队近期报道 Co-Scientist,一个基于 Gemini 的多智能体 scientific thinking engine,用 generate-debate-evolve 的流程生成和改进科学假说,并在 AML 药物再利用、肝纤维化靶点发现和抗菌耐药机制解释中进行实验或专家验证。
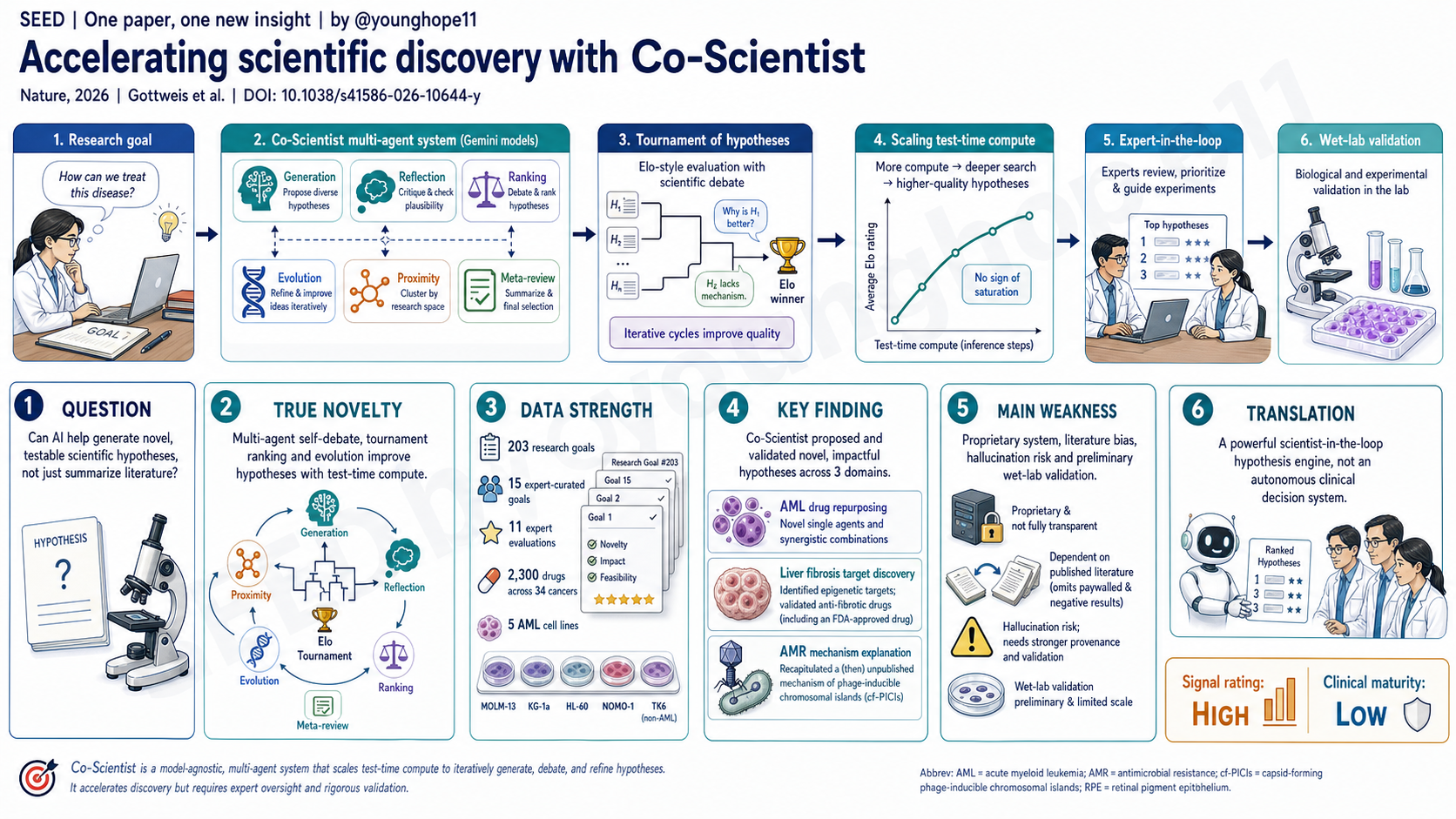
研究问题是什么?
这篇论文问的是:AI 能不能从“总结已有文献”进一步走到“提出新颖、合理、可实验验证的科学假说”?
科学发现通常需要两种能力:深入理解某个领域的机制细节,同时从其他领域找到非显然连接。人类专家能做到,但速度受限。Co-Scientist 的目标是让 AI 作为 scientist-in-the-loop 的协作者,在给定研究目标、约束和已有证据后,生成可测试假说、实验建议和转化分析。
真正的新意是什么?
新意在于它不是单个 deep research 工具,而是一个把科学方法拆成多个角色的多智能体系统。Co-Scientist 包括 generation、reflection、ranking、proximity、evolution 和 meta-review 等 agents。
系统生成假说后,会通过 reflection 检查正确性、可测试性和 novelty;ranking agent 用 tournament 和 scientific debate 比较假说;evolution agent 不断从强假说中生成改进版;meta-review 汇总整个过程。随着 test-time compute 增加,假说在 Elo-style tournament 中逐步改进。
它的定位也很重要:不是 autonomous scientist,而是 expert-in-the-loop。科学家设定目标、约束、偏好和最终实验优先级,AI 扩大搜索范围并提出候选路径。
数据强在哪里?
第一层是系统评估。作者在 203 个研究目标上分析 Co-Scientist 假说质量随 test-time compute 增长的变化,看到 top hypotheses 的 Elo rating 随时间提高。在 15 个由 7 位 biomedical experts 设计的复杂目标上,Co-Scientist 随迭代显著超过多个 frontier LLM/reasoning baselines。
第二层是专家评价。对 11 个专家评估目标,Co-Scientist 输出在偏好排序、novelty 和 impact 上优于对照模型。平均 preference rank 为 2.36,novelty 3.64/5,impact 3.09/5。作者也明确指出,这仍是主观专家评估,不是客观 ground truth。
第三层是 wet-lab validation。AML 药物再利用中,系统从 2,300 个 approved drugs 和 34 个 cancer types 的空间中产生候选,经专家筛选后在 4 个 AML cell lines 和一个 non-AML control line 中验证。Binimetinib、Pacritinib、Cerivastatin 显示细胞活性抑制;KIRA6 在 KG-1a 中 IC50 为 10 nM,相比 TK6 control 的 180 nM 有约 18 倍差异。Co-Scientist 还提出 7 个 AML drug combinations,其中 MOLM-13 中多个 doublet 和 triplet 显示 synergy。
第四层是跨问题验证。肝纤维化方向,Co-Scientist 提出 epigenetic targets 和对应药物,其中两个在 human hepatic organoids 中显示显著 anti-fibrotic activity 且无明显细胞毒性,包括已获 FDA 批准用于其他癌症适应症的 Vorinostat。抗菌耐药方向,系统在两天内独立提出 cf-PICIs 通过与多种 phage tails 相互作用扩大 host range 的机制,匹配一项当时尚未完成同行评审的独立实验发现。
最大弱点是什么?
最大弱点是验证仍然早期。AML 数据主要是细胞系 viability 和 combination assay;肝纤维化是 organoid level;AMR 是机制重现而非系统自己的新实验发现。它们足以证明系统能提出有价值假说,但还不能证明这些假说可以直接转化为治疗或临床决策。
第二个弱点是可复现性和开放性。Co-Scientist 深度依赖 Google 内部 infrastructure 和大规模 test-time compute,完整系统源码并未公开。论文提供了 pseudocode 和 prompts,但外部团队很难完整复现系统能力。
第三个弱点是文献依赖。系统会受 open-access literature、paywalled prior art、负结果缺失和文献质量混杂影响。即便有 reflection 和 search tools,hallucination、错误引用和 irreproducible literature propagation 仍是风险。
第四个弱点是科学文化层面。如果 AI 假说系统被过度信任,可能让研究方向同质化,或把看起来合理但未充分验证的想法包装成高质量科学产物。论文自己也警告,不当使用可能加剧 reproducibility crisis。
是否有临床转化意义?
有,但主要是 discovery workflow 的意义,不是直接临床应用。Co-Scientist 最适合的位置是帮助专家扩大假说空间、发现跨领域连接、给出初步实验优先级,并在早期 wet-lab 之前减少盲目筛选。
对 drug repurposing、combination therapy、target discovery 和 mechanism explanation 这类搜索空间很大的问题,它可以显著提高探索效率。尤其是当候选空间有限但组合数量巨大时,AI 假说生成可能比 brute-force wet-lab screening 更经济。
但它不能替代 preclinical pipeline,更不能替代 clinical trial。Co-Scientist 输出应被视为 hypothesis package,而不是医学建议。任何治疗相关结论都必须经过机制验证、动物模型、药代毒理、患者分层和临床试验。
Yang 的信号评级:High
理由:我会把科研信号评为 High。Co-Scientist 的核心价值是把 AI hypothesis generation 从“写一段好看的推理”推进到多智能体自我辩论、排序、演化和专家参与实验验证的结构化流程。
这个 High 的基础是三件事:test-time compute scaling 下假说质量持续提高,专家评估相对强,以及至少有三类 biomedical validation。弱点在于验证规模、系统闭源和临床距离,但这些不削弱它作为 AI-for-science workflow 的信号。
临床成熟度我会评为 Low。它已经能帮助设计和优先排序实验,但离临床可用系统还很远。当前更准确的定位是“科学家增强工具”,不是自动发现药物或自动做临床决策的系统。
Juraj Gottweis, Pushmeet Kohli, Annalisa Pawlosky, Alan Karthikesalingam, Vivek Natarajan and colleagues at Google Cloud AI Research, Google DeepMind, Google Research and partner institutions recently reported Co-Scientist, a Gemini-based multi-agent scientific thinking engine that generates and improves hypotheses through a generate-debate-evolve workflow, with validation in AML drug repurposing, liver-fibrosis target discovery and antimicrobial-resistance mechanism explanation.
What is the research question?
This paper asks whether AI can move beyond summarizing the literature and help generate scientific hypotheses that are novel, plausible and experimentally testable.
Scientific discovery requires both deep domain expertise and the ability to connect distant fields. Human experts can do this, but slowly. Co-Scientist is designed as a scientist-in-the-loop collaborator that takes a research goal, constraints and prior evidence, then proposes hypotheses, experimental plans and translational analyses.
What is truly new?
The novelty is that Co-Scientist is not a single deep-research agent. It decomposes scientific reasoning into a multi-agent workflow with generation, reflection, ranking, proximity, evolution and meta-review agents.
After hypotheses are generated, reflection checks correctness, testability and novelty. The ranking agent compares hypotheses in a tournament with scientific debate. The evolution agent creates improved variants from stronger ideas. Meta-review summarizes patterns across the whole process. As test-time compute increases, hypotheses improve in an Elo-style tournament.
The positioning matters: this is not an autonomous scientist. It is an expert-in-the-loop system. Scientists set goals, constraints, preferences and final experimental priorities, while the AI broadens the search space and proposes candidate paths.
Where is the data strongest?
The first layer is system evaluation. Across 203 research goals, the authors show that hypothesis quality improves with test-time compute, as measured by Elo ratings of top hypotheses. In 15 complex goals curated by seven biomedical experts, Co-Scientist eventually outperformed several frontier LLM and reasoning-model baselines.
The second layer is expert evaluation. Across 11 expert-evaluated goals, Co-Scientist outputs were preferred and rated higher for novelty and impact than baseline models. The average preference rank was 2.36, with novelty at 3.64 out of 5 and impact at 3.09 out of 5. The authors correctly note that these are subjective expert judgments, not objective ground truth.
The third layer is wet-lab validation. For AML drug repurposing, the system explored 2,300 approved drugs across 34 cancer types, then expert-selected candidates were tested in four AML cell lines and one non-AML control line. Binimetinib, Pacritinib and Cerivastatin inhibited cell viability. KIRA6 showed an IC50 of 10 nM in KG-1a cells compared with 180 nM in TK6 controls, suggesting an approximately 18-fold separation. Co-Scientist also proposed seven AML drug combinations, several of which showed synergy in MOLM-13 cells.
The fourth layer is cross-problem validation. In liver fibrosis, Co-Scientist proposed epigenetic targets and corresponding drugs; two showed significant anti-fibrotic activity in human hepatic organoids without obvious cytotoxicity, including the FDA-approved cancer drug Vorinostat. In antimicrobial resistance, the system independently proposed in two days that cf-PICIs interact with diverse phage tails to expand host range, matching an independent experimental discovery that had not yet completed peer review.
What is the biggest weakness?
The biggest weakness is that validation remains early. The AML work is mainly cell-line viability and combination testing. The fibrosis work is at the organoid level. The AMR example is a recapitulation of a mechanism rather than a new experiment performed by the system. These are enough to show useful hypothesis generation, but not enough to establish clinical translation.
A second weakness is reproducibility and openness. Co-Scientist depends deeply on Google infrastructure and large-scale test-time compute. The full source code is not public. The paper provides pseudocode and prompts, but external teams cannot fully reproduce the system.
A third weakness is literature dependence. The system is constrained by open-access literature, missing paywalled prior art, limited access to negative results and mixed source quality. Even with reflection and search tools, hallucination, citation errors and propagation of irreproducible claims remain risks.
A fourth weakness is scientific culture. If overtrusted, AI hypothesis systems may homogenize research directions or make plausible but unvalidated ideas look like mature science. The paper itself warns that improper use could worsen the reproducibility crisis.
Is there translational or clinical relevance?
Yes, but mainly as a discovery workflow rather than a direct clinical application. Co-Scientist is most useful for helping experts expand the hypothesis space, find cross-field connections, prioritize early experiments and reduce blind wet-lab screening.
For drug repurposing, combination therapy, target discovery and mechanism explanation, the search space is large and combinatorial. In those settings, AI-generated hypotheses may be more efficient than brute-force screening.
But Co-Scientist cannot replace the preclinical pipeline and certainly cannot replace clinical trials. Its outputs should be treated as hypothesis packages, not medical recommendations. Treatment-related claims still need mechanistic validation, animal models, pharmacology, toxicology, patient stratification and clinical trials.
Yang’s signal rating: High
Reason: I would rate the scientific signal as High. Co-Scientist advances AI hypothesis generation from plausible prose into a structured workflow with multi-agent debate, ranking, evolution and expert-in-the-loop experimental validation.
The High rests on three elements: hypothesis quality improves with test-time compute, expert evaluations are relatively strong and there are three forms of biomedical validation. The weaknesses around validation scale, closed infrastructure and clinical distance are real, but they do not undermine the signal as an AI-for-science workflow.
Clinical maturity is Low. The system can help design and prioritize experiments, but it is far from clinical use. Its best current description is a scientist-augmentation tool, not an autonomous drug-discovery or clinical-decision system.