SEED | 让 AI 在科学软件里试错 SEED | AI tree search writes empirical software AI-assisted · reviewed
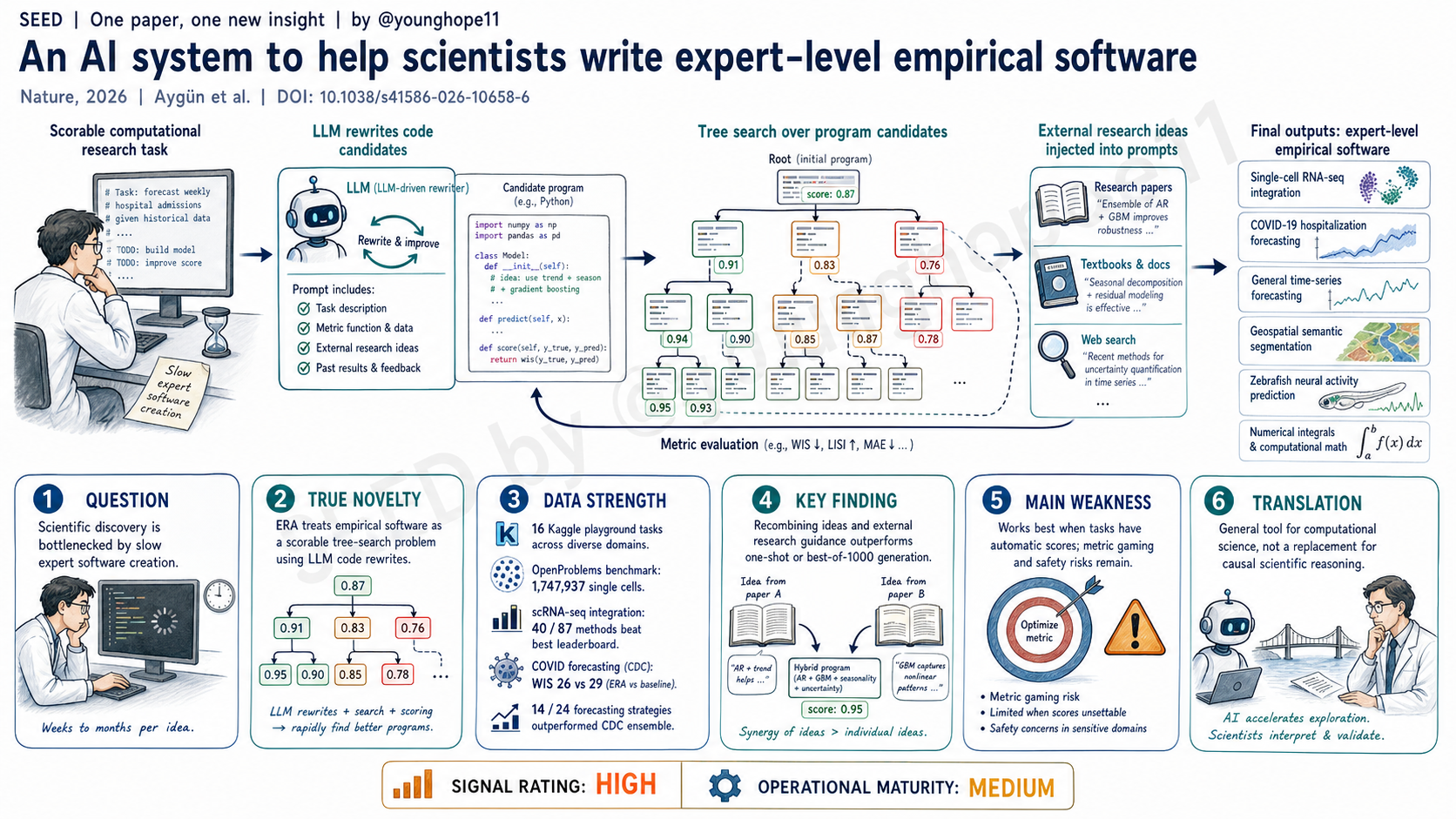
Google DeepMind、Google Research 与 Harvard 的 Eser Aygün、Shibl Mourad、Michael P. Brenner 团队近期报道 ERA,一个把 empirical scientific software 写作转化为可评分搜索问题的 AI 系统,在单细胞数据整合、COVID 住院预测、时间序列、遥感、神经活动预测和数值积分等任务上生成了 expert-level 软件。
研究问题是什么?
这篇论文问的是一个 AI for science 里很实际的问题:科学发现中大量瓶颈并不在“想不到问题”,而在写不出足够好的 empirical software。很多科学任务需要构造模型、特征、评估流程、数值方法和数据处理代码,然后通过反复试错来最大化某个质量指标。
传统科学软件开发依赖专家经验,通常很慢,而且探索范围有限。ERA 的目标不是直接替代科学理论推理,而是处理一类更明确的问题:当一个科学任务可以被自动评分时,AI 能不能像专家一样不断写、改、测代码,并在大量候选程序中找到高分方案?
真正的新意是什么?
真正的新意是把“写科学软件”定义成一个 scorable task。ERA 用 LLM 做语义级 code rewrite,用 tree search 管理候选程序树,并用自动评分函数决定哪些分支值得继续探索。
这和一次性代码生成不同。ERA 不是问模型一次“请写一个最佳程序”,而是让模型不断修改已有候选代码,提交评分,再根据分数选择下一批节点。它还可以把论文、教材、搜索结果或其他 AI research agents 给出的想法注入 prompt,让系统在已有科学思路之间 recombine。
因此,ERA 更像一个高速试错引擎:人类提供任务、数据和评分规则,AI 负责大规模探索软件实现和想法组合。
数据强在哪里?
强在任务覆盖面和自动评分都比较硬。作者先用 16 个 Kaggle playground competitions 校准系统,显示 ERA 优于 single LLM call、best-of-1000 LLM calls 和 AIDE。
在单细胞 RNA-seq batch integration 上,ERA 使用 OpenProblems v2.0.0 benchmark,在 6 个 human/mouse datasets、13 个指标、共 1,747,937 个细胞上评估。它对 9 个已有方法中的 8 个生成了超过对应 published result 的实现;其中 BBKNN tree-search 版本比最佳已发表方法 ComBat 的 overall score 提高 14%,并在每个数据集和 11/13 个指标上达到或超过原 BBKNN。
更重要的是,ERA 不只是复制方法。它系统生成 55 个方法组合,其中 24 个超过两个 parent methods,另有 22 个超过其中一个 parent。结合 base methods、recombination、Deep Research 和 AI co-scientist idea 后,87 个候选中的 40 个超过当时 OpenProblems leaderboard 上全部已发表方法。
在 COVID-19 hospitalization forecasting 上,ERA 在 2024-2025 season 的 retrospective rolling validation 中达到平均 WIS 26,优于官方 CovidHub Ensemble 的 29。它还产生 14 个超过 CDC ensemble 的策略,其中 10 个来自模型重组。
此外,ERA 在 GIFT-Eval 时间序列 benchmark、geospatial segmentation、zebrafish neural activity prediction 和 numerical integrals 上也达到 expert-level performance。
最大弱点是什么?
最大弱点是它依赖“可评分”。ERA 在有明确 metric、可以快速运行和比较代码输出的任务上很强,但科学发现并不总是这样。很多真正重要的问题需要因果解释、实验设计、理论约束和长期验证,不能被一个 leaderboard score 完整代表。
第二个问题是 metric gaming。只要自动评分成为优化目标,系统就可能学会对 benchmark 特化,而不是学会更一般的科学理解。作者用了 holdout benchmark、人工代码检查和多领域任务来降低这个风险,但这仍是所有自动化搜索系统的核心问题。
第三个问题是安全和责任。ERA 降低了复杂经验软件的门槛,这对有益科学很重要,但也会降低敏感领域中高性能模型、预测系统或工程流程的部署门槛。论文也强调,这类能力需要在敏感应用中有明确 guardrails 和人工审查。
是否有临床转化意义?
如果按传统“临床成熟度”衡量,这不是一篇临床论文。但它有明显的科研基础设施意义:凡是能把任务定义为数据、代码和可自动计算的质量指标,ERA 这样的系统都可能显著加快探索。
对生物医学尤其相关的是单细胞数据整合、流行病预测、成像分割、神经数据建模和算法设计。它不会自动给出临床结论,但可以更快地产生候选分析方法和预测模型,再交给科学家验证。
真正的转化边界在于:ERA 适合作为 computational exploration engine,不适合作为无人监督的科学判断者。科学家仍需要决定问题是否值得优化、metric 是否合理、模型是否可解释、结果是否能跨数据和实验复现。
Yang 的信号评级:High
理由:我会把科研信号评为 High。它的贡献不是“又一个 coding agent”,而是把 empirical software creation 明确框定为 LLM rewrite + tree search + automatic scoring + idea recombination 的通用科研工作流,并在多个公开 benchmark 上给出强结果。
这个 High 不是说 ERA 已经能自动做完整科学发现,而是说它在“可评分科学软件”这个子问题上给了一个强框架。它把试错速度从 weeks/months 压到 hours/days,这对 computational science 的影响可能很大。
临床成熟度不适用。若换成“科研工作流成熟度”,我会评为 Medium:结果很强,但实际使用仍取决于 metric 设计、数据泄漏控制、benchmark 外泛化、安全审查和科学家的最终判断。
Eser Aygün, Shibl Mourad, Michael P. Brenner and colleagues at Google DeepMind, Google Research and Harvard recently reported ERA, an AI system that turns empirical scientific software creation into a scorable search problem and generates expert-level software across single-cell integration, COVID hospitalization forecasting, time-series forecasting, geospatial analysis, neural activity prediction and numerical integration.
What is the research question?
This paper asks a practical question for AI for science: many scientific projects are not limited only by ideas, but by the slow creation of empirical software. Models, feature pipelines, numerical methods and data-processing code often need expert iteration to maximize a measurable quality score.
Traditional scientific software development is slow and strongly shaped by expert intuition. ERA does not try to replace scientific theory. It targets a more concrete problem: when a scientific task can be automatically scored, can an AI system keep writing, modifying and testing code until it finds expert-level solutions?
What is truly new?
The real novelty is defining scientific software creation as a scorable task. ERA uses an LLM to perform semantic code rewrites, tree search to manage candidate programs and automatic evaluation to decide which branches deserve more exploration.
This is different from one-shot code generation. ERA does not ask a model once for the best program. It repeatedly mutates existing candidates, scores them and expands the program tree. It can also inject ideas from papers, textbooks, search results or other AI research agents, allowing the system to recombine scientific strategies.
ERA is therefore a high-speed exploration engine: humans provide the task, data and metric, while the AI searches across implementations and idea combinations.
Where is the data strongest?
The strongest evidence is the breadth of tasks and the use of hard automatic scoring. The authors first calibrate the system on 16 Kaggle playground competitions, where ERA outperforms a single LLM call, best-of-1000 LLM calls and AIDE.
For single-cell RNA-seq batch integration, ERA is evaluated on the OpenProblems v2.0.0 benchmark across six human and mouse datasets, 13 metrics and 1,747,937 cells. It produced implementations that outperformed the corresponding published result for eight of nine methods. Its BBKNN tree-search implementation improved overall score by 14% over the best published method, ComBat, and matched or exceeded published BBKNN on every dataset and 11 of 13 metrics.
ERA also went beyond replication. Among 55 method recombinations, 24 outperformed both parent methods and another 22 outperformed one parent. Across base methods, recombinations, Deep Research ideas and AI co-scientist ideas, 40 of 87 generated methods beat all methods then published on the OpenProblems leaderboard.
For COVID-19 hospitalization forecasting, ERA achieved an average WIS of 26 in retrospective rolling validation across the 2024-2025 season, outperforming the official CovidHub Ensemble at 29. It generated 14 distinct strategies that beat the CDC ensemble, 10 of which came from recombination.
ERA also achieved expert-level performance on GIFT-Eval time-series forecasting, geospatial segmentation, zebrafish neural activity prediction and numerical integrals.
What is the biggest weakness?
The biggest weakness is dependence on scoring. ERA is strongest when a task has a clear metric, can be run quickly and can compare code outputs automatically. Many important scientific questions do not fit that shape. They require causal explanation, experimental design, theory and long-term validation that cannot be reduced to a leaderboard score.
A second issue is metric gaming. Once the automatic score becomes the objective, the system may specialize to a benchmark instead of learning broader scientific understanding. The paper uses holdout benchmarks, human code inspection and multiple domains to reduce this risk, but it remains central to automated search.
A third issue is safety and responsibility. ERA lowers the expertise needed to create sophisticated empirical software. That can accelerate beneficial science, but it can also lower the barrier for powerful models and prediction systems in sensitive domains. This capability needs guardrails and human review.
Is there translational or clinical relevance?
This is not a clinical paper in the usual sense. Its translational value is as scientific infrastructure: whenever a research problem can be framed as data, code and an automatically computed quality metric, systems like ERA may greatly accelerate exploration.
For biomedicine, the relevant applications include single-cell integration, epidemiological forecasting, image segmentation, neural data modeling and algorithm design. ERA will not by itself establish clinical truth, but it can quickly produce candidate methods and models for scientists to validate.
The boundary is clear. ERA is best viewed as a computational exploration engine, not an unsupervised scientific judge. Scientists still need to decide whether the metric is valid, whether leakage is controlled, whether the model generalizes and whether the result can be reproduced outside the benchmark.
Yang’s signal rating: High
Reason: I would rate the scientific signal as High. The contribution is not just another coding agent. It frames empirical software creation as a general workflow combining LLM rewriting, tree search, automatic scoring and idea recombination, then supports that framing across multiple public benchmarks.
This High does not mean ERA can do full scientific discovery autonomously. It means the paper gives a strong framework for the narrower but important problem of scorable scientific software. Reducing exploration from weeks or months to hours or days could matter a lot for computational science.
Clinical maturity is not applicable. If reframed as research-workflow maturity, I would rate it Medium: the results are strong, but practical deployment still depends on metric design, leakage control, out-of-benchmark generalization, safety review and final scientific judgment by humans.