SEED AI | AI 靶点发现:快在排序,慢在验证 SEED AI | AI target discovery is fast at ranking, slow at validation AI-assisted · reviewed
Frank W. Pun、Feng Ren、Alex Zhavoronkov 等人近期在 Nature Reviews Drug Discovery 发表 Review,系统梳理 AI 如何进入 therapeutic target identification and assessment。这篇文章值得读,不是因为它证明 AI 靶点发现已经产生获批药物,而是因为它把 AI 放进靶点发现价值链,帮助判断哪些环节真的能加速,哪些仍被验证成本卡住。
为什么靶点发现需要 AI
靶点发现适合被 AI 介入,根本原因是信息太多、证据太碎、候选空间太大。人类有约 20,000 个蛋白编码基因,其中约 4,500 个被认为具有 druggable potential,但截至目前已获批药物只作用于 716 个不同靶点。真正的问题不是“有没有候选靶点”,而是哪些候选值得进入昂贵的实验和临床验证。
这篇 Review 的主瓶颈是 evidence too fragmented,次瓶颈是 too much data 和 experiments too slow。AI 进入的位置主要在 target discovery 和 target assessment:整合 omics、文献、知识图谱、影像、临床数据、专利和竞争格局,帮助形成靶点假说、评估 druggability / safety / tractability,并决定下一步验证优先级。
真正的新意是把靶点发现变成可排序的证据管线
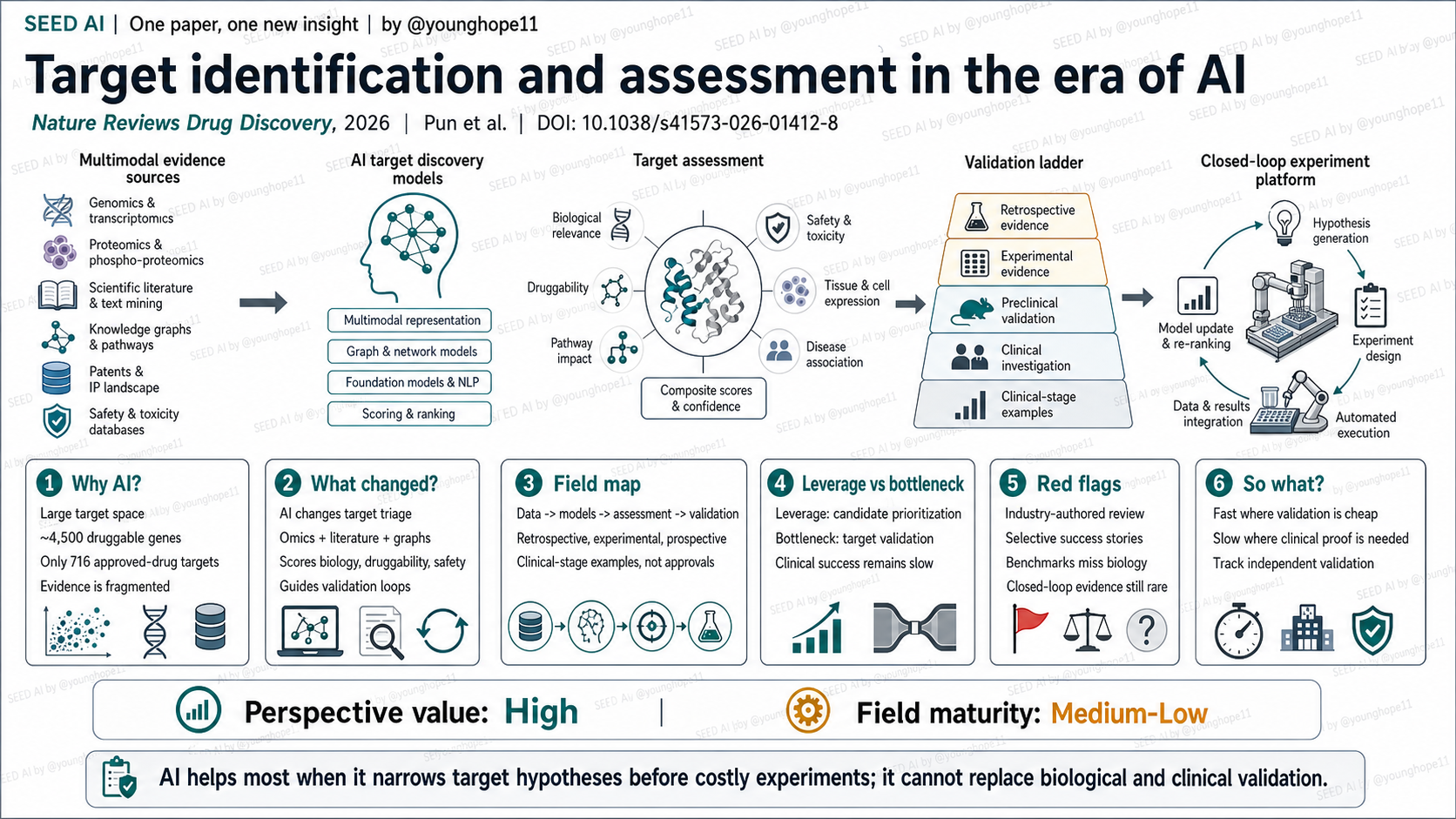
这篇文章的新意不在于提出单个新模型,而在于把 AI 靶点发现整理成一条完整价值链:数据输入 -> 表征与建模 -> 靶点评估 -> 回顾性 / 实验 / 前瞻性验证 -> 闭环实验平台。
AI 改变的不是“生物学事实本身”,而是候选靶点的 triage 过程。传统靶点发现依赖专家从分散证据中形成假说;AI 可以把多组学、PPI 网络、GWAS、cellular imaging、literature mining、clinical trial records 和 patent landscape 放进同一个评分框架,给每个靶点形成 biology、druggability、safety、novelty、commercial tractability 和 validation feasibility 的综合判断。
但这也意味着 AI 的真实价值主要在“减少盲筛和排序错误”,不是替代生物学验证。一个模型把靶点排到前面,只说明它值得被验证,不说明它已经是有效治疗靶点。
领域地图清楚,证据层级必须分开看
这篇 Review 最强的是领域地图。它把数据源分成 omics、cellular imaging、PPI / pathway networks、clinical / phenotypic data、scientific literature、patents、regulatory filings 和 market reports;把模型分成 supervised / unsupervised learning、representation learning、GNN、generative AI、foundation models、LLM / agent systems 和 automation labs;再把验证分成 retrospective、experimental 和 prospective 三层。
证据层级上,最靠前的是 retrospective validation,例如用历史数据测试模型能否预测后来进入临床阶段的靶点。更强一层是 experimental validation,例如 CRISPR、细胞模型、动物模型验证 AI 预测靶点的功能相关性。最高层是 prospective / clinical validation,也就是靶点相关药物在人体研究和监管路径中被证明有价值。
文章列出了一些 AI 支持靶点发现进入临床阶段的案例:TNIK / IPF 是 Insilico 的代表案例,INS018_055 已完成早期安全性研究并报告 IIa 期安全性和 FVC 次要终点信号;APLNR / ageing 来自 BioAge 的 human-data-driven 方向,但 azelaprag 与 tirzepatide 联合的 II 期肥胖试验因肝酶升高而终止;PIKfyve / ALS 来自 Verge,但 VRG50635 因疗效不足而终止;DRD2 / ONC201 则是 AI 支持 target deconvolution 的例子,后来 dordaviprone 获批时关键机制又不完全等同于 DRD2。
别误读第一点:clinical-stage examples 不是 approved AI-discovered targets。别误读第二点:benchmark 强不等于靶点真能落地,因为靶点失败常发生在模型无法便宜验证的临床机制、毒性、患者分层和长期疗效上。
最重要的一点:AI 的杠杆在优先级排序,卡点在验证闭环
这篇 Review 最重要的边界判断是:AI 在靶点发现里最有用的地方,是把碎片化证据压缩成更好的候选排序,让团队少花钱验证低质量靶点。AI 可以显著提升“先看哪个靶点”的效率,尤其是在多组学、网络、文献和临床数据同时存在、但人类很难穷尽组合关系的场景。
卡点不在能不能生成更多候选,而在候选能不能通过验证闭环。靶点发现的答案并不便宜:细胞实验、动物模型、人源样本、毒性、药物可及性、临床终点和监管路径都需要时间和资金。文章自己也说,靶点最终验证来自基于该靶点药物的成功临床试验和监管批准。
所以这里的 AI 应用边界很清楚:当验证可以被自动化实验室、高内涵成像、多组学 perturbation 和快速 in vitro assay 便宜地关闭时,AI 靶点发现落地更快;当验证必须等人体临床疗效和安全性时,AI 只能提高先验概率,不能消除开发风险。
批判性阅读:行业综述、选择性案例和 benchmark 陷阱
第一条红旗是利益冲突。这篇 Review 的多位作者来自 Insilico Medicine、Astellas、BioAge 等公司,其中 Insilico 本身就在开发和使用 generative AI、下一代 AI 和机器人平台做药物发现。文章的领域地图有价值,但读者要意识到案例选择和叙事重心可能更偏向平台公司的成功路径。
第二条红旗是选择性成功故事。TNIK 是正面案例,但 APLNR 和 PIKfyve 也提醒我们,AI 支持的靶点进入临床不等于疗效成立。尤其是 PIKfyve / ALS 这样的失败案例,反而是判断 field maturity 的关键证据。
第三条红旗是 benchmark 与生物学之间的距离。文章讨论 TargetBench 等更接近临床可行性的 benchmark,但也指出传统 precision、recall、AUC-ROC 往往无法覆盖 disease-specific biological relevance 和 clinical feasibility。靶点发现不是一个普通分类题。
第四条红旗是数据质量和可复现性。文章引用 Cancer Biology Reproducibility Project 的结果,提醒文献数据本身可能有大量不可复现实验;如果 AI 在这些数据上建图和排序,模型可能只是更快地放大旧偏差。
对 AI 应用边界的启发
投资 / 合作判断上,我会更看重三类能力:第一,是否有高质量、可追溯、少偏差的多模态数据;第二,是否有能快速验证靶点功能的 wet-lab / automation closed loop;第三,是否愿意用独立前瞻性结果而不是内部 benchmark 证明模型。只有模型分数或漂亮 platform demo,信号不够。
科研方向跟踪上,可以重点看 TargetBench 这类更贴近 clinical feasibility 的 benchmark、automation lab 和 perturbation-based validation 的闭环平台,以及 AI 支持靶点进入临床后的真实 outcomes。最有价值的证据不是又多一个 top-ranked target,而是 AI 排名是否系统性提高了实验命中率和临床推进质量。
待解问题有两个:AI target discovery 能否在不同疾病和不同 modality 中稳定提高 hit-to-validation rate?以及平台公司能否公开足够多的失败案例,让外部判断模型是在学习可转化生物学,还是在学习既有文献和商业偏好?
Yang 的信号评级:Medium
轴一,视角价值:High。理由:这篇 Review 给出了完整的 AI 靶点发现地图,把数据源、模型类型、靶点评估标准、验证策略、临床阶段案例和闭环实验平台放在同一框架里,对建立判断坐标很有帮助。
轴二,领域成熟度:Medium-Low。理由:AI 已经能改进靶点排序、生成假说、辅助 druggability / safety / patentability 评估,并支持部分候选进入临床;但目前还没有真正来自 AI-driven target identification 的获批靶点,失败案例和验证成本说明领域仍在早期。
一句话总结:AI 靶点发现的真实价值是把“该验证什么”排得更好,而不是把靶点验证本身变便宜到可以跳过。
Frank W. Pun, Feng Ren, Alex Zhavoronkov and colleagues recently published a Review in Nature Reviews Drug Discovery on how AI is entering therapeutic target identification and assessment. The paper is worth reading not because it proves that AI-discovered targets have already produced approved drugs, but because it places AI inside the target-discovery value chain and helps separate where AI can accelerate decisions from where validation cost still dominates.
Why target discovery invites AI
Target discovery invites AI because there is too much information, too much fragmented evidence and too large a candidate space. Humans have roughly 20,000 protein-coding genes, about 4,500 of which are considered druggable, yet approved drugs act through only 716 distinct targets. The real question is not whether more candidate targets can be listed, but which candidates deserve expensive experimental and clinical validation.
The primary bottleneck is fragmented evidence. Secondary bottlenecks are too much data and slow experimentation. AI enters mainly at target discovery and target assessment: integrating omics, literature, knowledge graphs, imaging, clinical data, patents and competitive landscapes to form target hypotheses, assess druggability, safety and tractability, and decide what should be validated next.
What changed is target triage
The novelty of this Review is not one new model. It is the organization of AI target discovery into a full value chain: data input -> representation and modelling -> target assessment -> retrospective, experimental and prospective validation -> closed-loop experimental platforms.
AI does not change biological reality. It changes the triage process for candidate targets. Traditional target discovery relies on experts forming hypotheses from scattered evidence. AI can place multi-omics, PPI networks, GWAS, cellular imaging, literature mining, clinical trial records and patent landscapes into a shared scoring framework, producing a combined view of biology, druggability, safety, novelty, commercial tractability and validation feasibility.
That also defines the boundary. A target ranked highly by a model is a better candidate for validation, not a validated therapeutic target.
The field map is useful, but evidence levels must stay separate
The strongest contribution of this Review is the field map. It organizes data sources into omics, cellular imaging, PPI and pathway networks, clinical and phenotypic data, scientific literature, patents, regulatory filings and market reports. It organizes models into supervised and unsupervised learning, representation learning, GNNs, generative AI, foundation models, LLM or agent systems, and automation labs. It then separates validation into retrospective, experimental and prospective levels.
The evidence ladder matters. The earliest layer is retrospective validation, such as testing whether historical models would have predicted targets that later entered clinical development. A stronger layer is experimental validation, such as CRISPR, cellular models or animal studies that test functional relevance. The highest layer is prospective and clinical validation, where target-linked drugs show value in human studies and regulatory paths.
The article highlights several clinical-stage AI-supported examples. TNIK in idiopathic pulmonary fibrosis is the Insilico example, with INS018_055 completing early safety studies and reporting phase IIa safety plus forced vital capacity signals as a secondary endpoint. APLNR in ageing is linked to BioAge’s human-data-driven approach, but the azelaprag plus tirzepatide phase II obesity trial was terminated after liver enzyme elevations. PIKfyve in ALS is linked to Verge, but VRG50635 was terminated for insufficient efficacy. DRD2 and ONC201 illustrate AI-supported target deconvolution, although dordaviprone’s 2025 approval in H3 K27M-mutant diffuse midline glioma is tied to a mechanism not reducible to DRD2 alone.
Do not misread this in two ways. First, clinical-stage examples are not approved AI-discovered targets. Second, benchmark strength does not equal target deployability, because target failure often appears in clinical mechanism, toxicity, patient selection and long-horizon efficacy.
The leverage is prioritization; the bottleneck is validation closure
The most important boundary judgment is that AI is most useful in target discovery when it compresses fragmented evidence into better prioritization. It can help teams spend less money validating poor targets. Its value is strongest when many data types exist but humans cannot exhaustively reason over their combinations.
The bottleneck is not whether AI can generate more candidates. It is whether those candidates can pass validation closure. Target discovery answers are not cheap: cell experiments, animal models, human samples, toxicity, druggability, clinical endpoints and regulatory pathways all require time and capital. The Review itself emphasizes that the ultimate validation of a target comes from successful clinical trials and regulatory approval of a drug based on it.
This defines the AI application boundary. When validation can be closed cheaply through automation labs, high-content imaging, multi-omics perturbation and rapid in vitro assays, AI target discovery can move faster. When validation depends on human clinical efficacy and safety, AI can raise prior probability but cannot remove development risk.
Read it critically: industry perspective, selected examples and benchmark traps
The first red flag is conflict of interest. Several authors are affiliated with Insilico Medicine, Astellas, BioAge and other companies, and Insilico itself develops generative AI, next-generation AI and robotics platforms for drug discovery. The field map is valuable, but readers should treat example selection and narrative emphasis as partly shaped by platform-company perspectives.
The second red flag is selective success stories. TNIK is the positive case, but APLNR and PIKfyve show why clinical entry is not equivalent to clinical proof. The failed PIKfyve program is especially important for judging field maturity.
The third red flag is the distance between benchmarks and biology. The Review discusses emerging tools such as TargetBench, but it also notes that standard precision, recall and AUC-ROC often miss disease-specific biological relevance and clinical feasibility. Target discovery is not a generic classification problem.
The fourth red flag is data quality and reproducibility. The article points to the Cancer Biology Reproducibility Project as a warning that the literature itself contains many findings that cannot be replicated. If AI builds graphs and rankings from those inputs, it may amplify old biases faster.
What this implies for AI application boundaries
For investment and collaboration judgment, I would look for three capabilities: high-quality multimodal data with traceable provenance, wet-lab or automation closed loops that can test target function quickly, and a willingness to prove model value through independent prospective results rather than internal benchmarks alone. Model scores or polished platform demos are not enough.
For research tracking, I would follow benchmarks closer to clinical feasibility such as TargetBench, automation-lab and perturbation-based closed-loop validation platforms, and the real outcomes of AI-supported targets after they enter clinical development. The most valuable evidence is not another top-ranked target; it is whether AI ranking systematically improves hit-to-validation rate and clinical progression quality.
Two open questions matter. Can AI target discovery reliably improve hit-to-validation rate across diseases and therapeutic modalities? And can platform companies disclose enough failures for outsiders to judge whether the models are learning translatable biology or merely learning literature and commercial priors?
Yang’s signal rating: Medium
Axis one, perspective value: High. Reason: the Review provides a complete map of AI target discovery, placing data sources, model families, target-assessment criteria, validation strategies, clinical-stage examples and closed-loop experimental platforms in one framework.
Axis two, field maturity: Medium-Low. Reason: AI can already improve target ranking, generate hypotheses, support druggability, safety and patentability assessment, and help move some candidates into clinical development. But there is still no approved target that clearly originated from AI-driven target identification, and both failures and validation cost show that the field remains early.
One-sentence summary: AI target discovery is valuable when it improves what to validate next, not when it makes target validation cheap enough to skip.