SEED AI | ERA:AI 真正快在可打分试错 SEED AI | ERA shows where AI scientific trial-and-error gets fast AI-assisted · reviewed
Google DeepMind、Google Research 与 Harvard 的 Eser Aygün、Shibl Mourad、Michael P. Brenner 团队近期在 Nature 报道 ERA,一个用 LLM 代码改写、tree search 和自动评分来生成 expert-level empirical scientific software 的 AI 系统。这篇文章值得读,不只是因为它又做了一个 coding agent,而是因为它非常清楚地揭示了 AI 在科学里的一个应用边界:当任务能被机器便宜评分时,AI 可以极快试错;当科学问题不能被可靠 metric 表达时,落地速度会明显下降。
为什么科学软件适合被 AI 介入
这篇论文面对的瓶颈不是“科学家不会写代码”,而是 empirical software 的开发长期卡在专家时间、试错成本和巨大解空间上。单细胞数据整合、传染病预测、神经活动建模、遥感分割和数值积分这类任务,都需要反复设计特征、模型、预处理、后处理和评估流程。
AI 介入的主因是搜索空间太大,次因是实验太慢,不过这里的“实验”主要是计算实验。价值链位置也很明确:ERA 不是做靶点发现或临床决策,而是进入 basic understanding / modeling 和科研软件生成这一段,把“写软件”变成可评分、可迭代、可自动搜索的流程。
真正的新意是把代码写作变成科学试错引擎
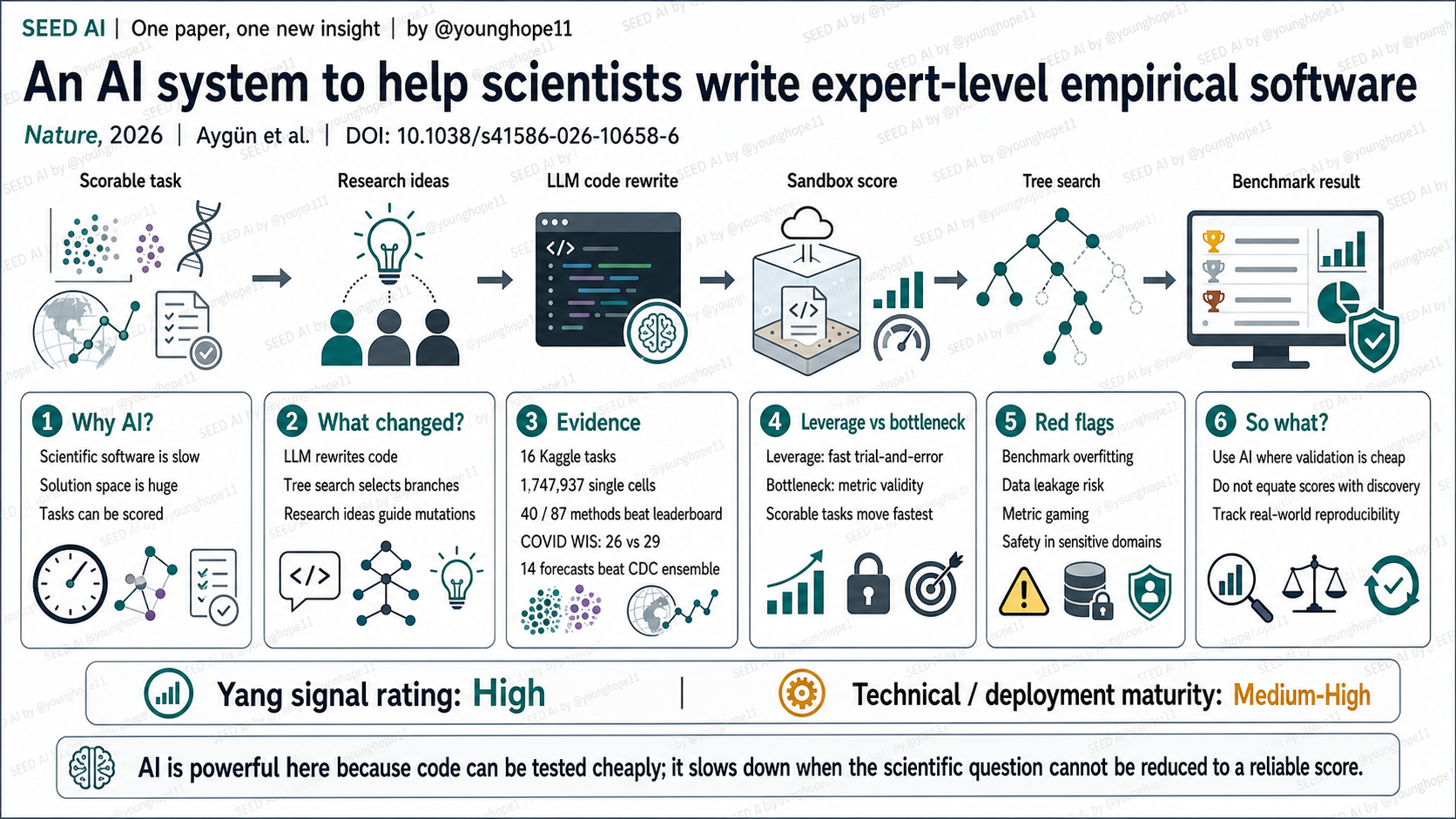
ERA 改变的是科学工作流里的软件生成步骤。它不是让 LLM 一次性写一个答案,而是让 LLM 重写已有候选代码,在 sandbox 里运行并打分,再用 tree search 决定哪些分支继续探索。
这一步很关键,因为很多科学软件不是靠一次灵感写出来,而是靠大量小改动和组合。ERA 可以把论文、教材、搜索结果、Deep Research 或 AI co-scientist 生成的想法注入 prompt,让模型在已有研究方法之间复制、组合和变异。
所以它真正改变的不是“发现了某个新的生物机制”,而是把专家手工试错变成高速、可记录、可回溯的 computational exploration。
证据强在多任务、硬指标和公开验证
这篇的最强证据形态是跨领域可评分任务的公开 benchmark。作者先用 16 个 Kaggle Playground competitions 调试系统,然后在六类科学任务上验证,包括 scRNA-seq batch integration、COVID-19 hospitalization forecasting、GIFT-Eval 时间序列、geospatial segmentation、zebrafish neural activity prediction 和 numerical integrals。
在单细胞任务上,ERA 使用 OpenProblems v2.0.0 benchmark,在 6 个 human/mouse 数据集、13 个指标、共 1,747,937 个细胞上评估。ERA 对 9 个已有方法中的 8 个生成了超过对应 published result 的实现,最佳 BBKNN tree-search 版本比当时最佳已发表方法 ComBat 的 overall score 提高 14%;综合 base methods、recombination、Deep Research 和 AI co-scientist ideas 后,87 个候选里有 40 个超过 OpenProblems leaderboard 上所有已发表方法。
在 COVID 住院预测上,ERA 做的是严格的 retrospective rolling validation:用 2025 年 5 月 1 日可得数据,对 2024-2025 season 做滚动预测。Google Retrospective 模型平均 WIS 为 26,优于官方 CovidHub ensemble 的 29;系统还生成 14 个超过 CDC ensemble 的策略,其中 10 个来自模型重组。
别误读第一点:这不是湿实验验证,也不是临床部署验证,而是计算任务上的强 benchmark 证据。别误读第二点:benchmark 强不等于完整科学发现,因为系统优化的是给定 metric,而不是自动判断问题是否重要、metric 是否代表真实机制。
最重要的一点:杠杆在便宜验证,卡点在 metric 是否可信
ERA 最有价值的边界判断是:AI 在科学里真正快的地方,是答案可以被便宜、客观、自动地验证。只要一个任务可以写成“输入数据、运行代码、计算质量分数”,AI 就能把试错从 weeks/months 压到 hours/days。
但卡点也同样清楚:metric validity。一个系统可以把 leaderboard 分数推高,并不意味着它理解了生物机制、因果关系或现实部署约束。metric 设计得越窄,AI 越可能找到高分技巧;metric 越接近真实科学目标,AI 的输出才越有价值。
这正好回到 AI 应用边界的主线:可执行、可评分、可重复运行的计算任务,AI 落地快;需要长期实验、因果解释、跨环境泛化和责任判断的任务,AI 仍然慢。
批判性阅读:泛化、泄漏、metric gaming 和安全
第一条红旗是泛化。ERA 在多个公开 benchmark 上表现很强,但这些仍然是 scorable tasks。真正要看的是它能否在新数据、新实验室、新疾病和真实科研流程中稳定提高产出,而不是只在已有 leaderboard 上找到高分程序。
第二条红旗是数据泄漏和 benchmark 过拟合。论文做了 holdout 设计、滚动验证和人工代码检查,但任何自动搜索系统都需要防止无意间从公开 benchmark、历史提交、论文摘要或 evaluation code 中学到不该学的线索。
第三条红旗是 metric gaming。ERA 的优势正来自自动评分,因此也天然容易把 metric 当作最终目标。科研使用时必须先问:这个 score 是否真的代表生物信号、公共卫生价值或可复现的科学结论?
第四条红旗是安全。作者也明确指出,自动生成 expert-level empirical software 会降低复杂计算模型的部署门槛。在流行病预测、临床建模、合成生物学或其他敏感领域,必须有人工审查、权限控制和风险边界。
对 AI 应用边界的启发
投资 / 合作判断上,ERA 提醒我们要找“验证便宜”的工作流。好项目不是只说有 agent,而是能明确给出数据、评价函数、sandbox、反馈循环和人工审查。对于生物医药,单细胞分析、成像分析、流行病预测、药筛数据建模这类任务比开放式临床推理更适合先落地。
科研方向跟踪上,我会关注三件事:第一,ERA 这种 code-search 系统能否接入真实实验闭环;第二,metric 设计如何避免 benchmark overfitting;第三,系统生成的科学软件能否被外部团队复现、维护和解释。
待解问题有两个:哪些生物医学任务可以被转化为足够可靠的 scorable task?以及,AI 生成的软件如果在真实科研或公共卫生场景中出错,责任应该落在任务设计者、模型提供者,还是使用者?
Yang 的信号评级:High
轴一,信号强度:High。理由:ERA 把 LLM、tree search、自动评分和研究想法重组连接成一个通用 AI-for-science 工作流,并在多个公开、可量化任务上给出强结果,尤其是单细胞和流行病预测两个生物医学相关任务。
轴二,技术/落地成熟度:Medium-High。理由:在可评分计算任务上,它已经接近可用工作流,且有公开参考实现和候选解;但广泛落地仍取决于 metric 质量、数据泄漏控制、benchmark 外泛化、安全审查和人类科学家的最终判断。
一句话总结:ERA 说明 AI 最先改变的不是完整科学发现,而是那些能被便宜评分的科学软件试错环节。
Eser Aygün, Shibl Mourad, Michael P. Brenner and colleagues at Google DeepMind, Google Research and Harvard recently reported ERA in Nature, an AI system that uses LLM code rewriting, tree search and automatic scoring to generate expert-level empirical scientific software. The paper is worth reading not because it is another coding agent, but because it reveals a sharp AI application boundary in science: when outputs can be scored cheaply by machines, AI can explore very quickly; when the scientific question cannot be reduced to a reliable metric, deployment slows down.
Why scientific software invites AI
The bottleneck here is not that scientists cannot code. It is that empirical software development is constrained by expert time, expensive trial-and-error and a huge solution space. Single-cell integration, disease forecasting, neural activity modelling, remote-sensing segmentation and numerical integration all require repeated design of features, models, preprocessing, postprocessing and evaluation pipelines.
The primary reason for AI intervention is that the search space is too large. A secondary reason is that experiments are slow, although here the experiments are mostly computational. The value-chain position is basic understanding and modelling, plus scientific software generation. ERA turns software writing into a scored, iterative and automatically searchable process.
What changed is the software-generation step
ERA changes the scientific workflow at the software-generation step. It does not ask an LLM for one final program. It asks the LLM to rewrite candidate code, executes the result in a sandbox, assigns a score and then uses tree search to decide which branches deserve more exploration.
That matters because many scientific programs are not created in one shot. They emerge from many small changes and combinations. ERA can inject ideas from papers, textbooks, search results, Deep Research or AI co-scientist into the prompt, then copy, combine and mutate existing research methods.
The contribution is therefore not a new biological mechanism. It is a fast, logged and revisitable computational exploration engine for expert scientific trial-and-error.
The evidence is strong where scoring is hard-edged
The strongest evidence shape is cross-domain performance on scorable public benchmarks. The authors first tuned the system on 16 Kaggle Playground competitions, then evaluated it on six scientific task families, including scRNA-seq batch integration, COVID-19 hospitalization forecasting, GIFT-Eval time-series forecasting, geospatial segmentation, zebrafish neural activity prediction and numerical integrals.
For single-cell integration, ERA used OpenProblems v2.0.0 with 6 human and mouse datasets, 13 metrics and 1,747,937 total cells. It generated implementations that beat the corresponding published result for 8 of 9 existing methods. The strongest BBKNN tree-search variant improved overall score by 14% over ComBat, the best published method at the time. Across base methods, recombinations, Deep Research and AI co-scientist ideas, 40 of 87 candidates beat all published methods on the OpenProblems leaderboard.
For COVID hospitalization forecasting, ERA used retrospective rolling validation with data available on 1 May 2025 across the 2024-2025 season. The Google Retrospective model achieved an average WIS of 26, better than the official CovidHub ensemble at 29. The system also generated 14 strategies that outperformed the CDC ensemble, 10 of which came from recombination.
Do not misread this in two ways. First, this is strong benchmark evidence for computational tasks, not wet-lab validation or clinical deployment. Second, benchmark strength does not equal scientific discovery, because the system optimizes a given metric rather than deciding whether the problem, metric or mechanism is scientifically sufficient.
The leverage is cheap validation; the bottleneck is metric validity
ERA’s most important boundary lesson is that AI gets fast in science when answers can be checked cheaply, objectively and automatically. If a task can be written as input data, executable code and a quality score, AI can compress trial-and-error from weeks or months to hours or days.
The bottleneck is metric validity. A system can drive leaderboard scores upward without understanding biological mechanism, causal structure or deployment constraints. The narrower the metric, the more the system may find score-specific tricks. The closer the metric is to the real scientific objective, the more valuable the output becomes.
This maps directly to a broader AI boundary: executable, scored and reproducible computational tasks can adopt AI quickly; tasks requiring long-horizon experiments, causal explanation, cross-environment generalization and responsibility judgments remain slower.
Read it critically: generalization, leakage, metric gaming and safety
The first red flag is generalization. ERA performs strongly across public benchmarks, but these are still scorable tasks. The next question is whether it improves output in new data, new labs, new diseases and real scientific workflows, not just known leaderboards.
The second red flag is data leakage and benchmark overfitting. The paper uses holdout designs, rolling validation and expert code inspection, but any automated search system must guard against accidental leakage from public benchmarks, historical submissions, paper summaries or evaluation code.
The third red flag is metric gaming. ERA’s strength comes from automatic scoring, so it can also turn the metric into the target. Scientific users need to ask whether the score really represents biological signal, public-health value or reproducible scientific insight.
The fourth red flag is safety. The authors explicitly note that expert-level empirical software lowers the barrier to sophisticated computational workflows. In disease forecasting, clinical modelling, synthetic biology or other sensitive domains, human review, access controls and risk boundaries matter.
What this implies for AI application boundaries
For investment or collaboration judgment, ERA suggests looking for workflows where validation is cheap. A serious project should define the data, evaluation function, sandbox, feedback loop and human review path. In biomedicine, single-cell analysis, imaging analysis, epidemic forecasting and drug-screen modelling are better early landing zones than open-ended clinical reasoning.
For research tracking, I would follow three questions: whether code-search systems can connect to real experimental loops, how metric design can prevent benchmark overfitting, and whether AI-generated scientific software can be reproduced, maintained and interpreted by outside teams.
Two open questions matter. Which biomedical tasks can be turned into reliable scorable tasks? And if AI-generated software fails in a real research or public-health setting, should accountability sit with the task designer, the model provider or the user?
Yang’s signal rating: High
Axis one, signal strength: High. Reason: ERA connects LLMs, tree search, automatic scoring and research-idea recombination into a general AI-for-science workflow, with strong results across public quantitative tasks, especially single-cell integration and epidemiological forecasting.
Axis two, technical / deployment maturity: Medium-High. Reason: for scorable computational tasks, this is close to a usable workflow, with a public reference implementation and generated candidate solutions. Broader deployment still depends on metric quality, leakage control, out-of-benchmark generalization, safety review and human scientific judgment.
One-sentence summary: ERA shows that AI will first transform the parts of science where software trial-and-error can be scored cheaply.