SEED AI | GPNMB CAR-T:AI 快在筛靶点,不快在证明安全 SEED AI | GPNMB CAR T shows AI is fast at target triage, not safety proof AI-assisted · reviewed
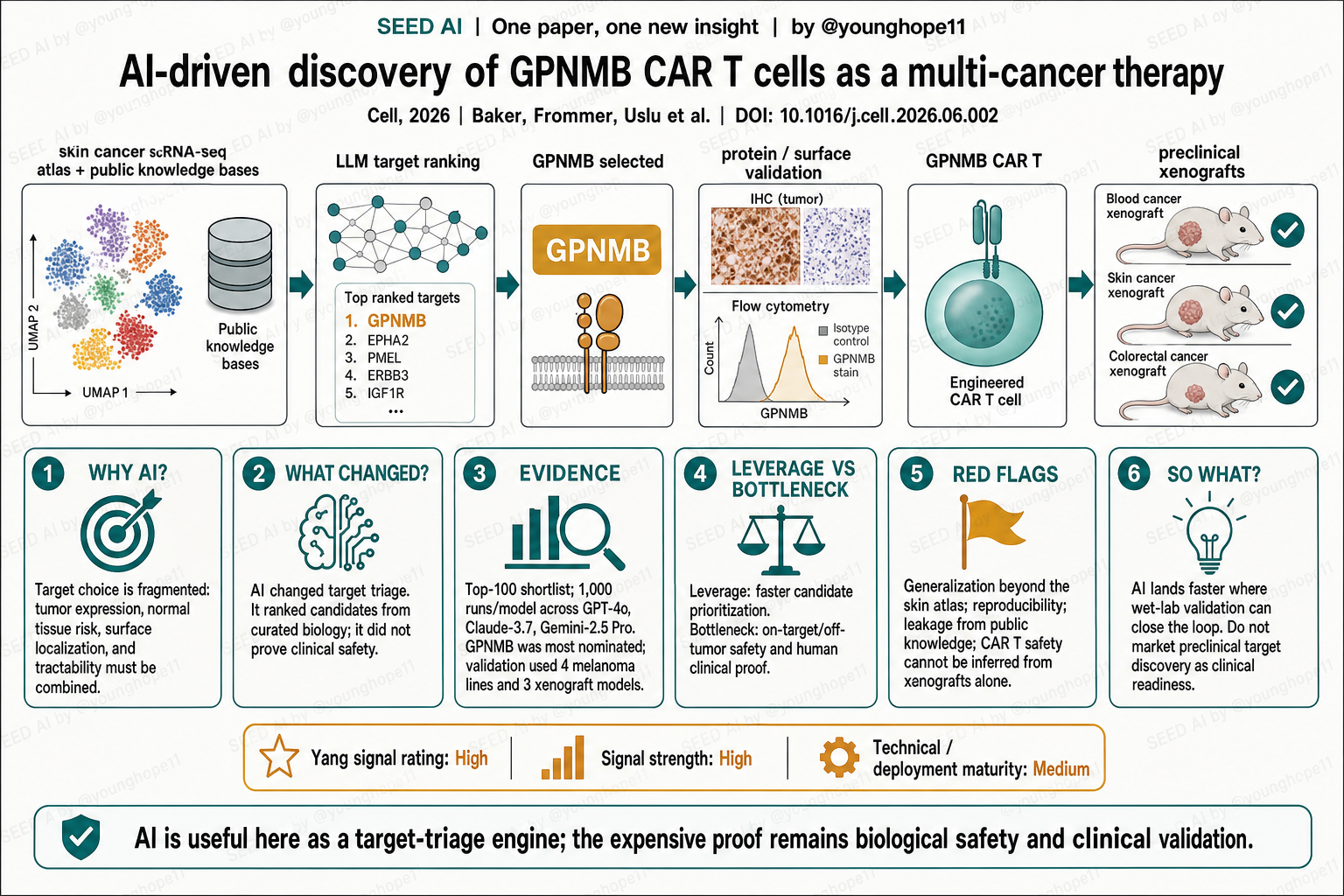
University of Pennsylvania、RWTH Aachen、Icahn School of Medicine at Mount Sinai 等团队近期在 Cell 报道了一套 AI 驱动的 CAR-T 靶点发现流程,并把 GPNMB 推进到 GPNMB CAR T 的临床前验证。这篇文章值得读,不是因为 LLM 直接“发明”了一个疗法,而是因为它把 AI 放在靶点发现这个证据很碎、验证很贵的环节里,清楚展示了 AI 在生物医药里最现实的一种用法:先降低候选排序成本,再用湿实验关闭验证环。
为什么 CAR-T 靶点发现需要 AI
这篇论文真正面对的瓶颈不是“能不能再做一个 CAR-T”,而是安全靶点太难找。一个理想 CAR-T 靶点要同时满足肿瘤表达高、正常关键组织表达低、位于细胞表面、有抗体或临床开发基础、最好还能覆盖足够多患者;这些证据分散在单细胞数据、GTEx、HPA、UniProt、Open Targets、ClinicalTrials.gov 和蛋白表达数据库里。
AI 介入的主因是证据太碎,次因是搜索空间太大、实验验证太慢。价值链位置也很明确:它进入的是 target discovery 到 preclinical validation 之间,先用数据整合和 LLM reasoning 压缩候选空间,再把少数候选交给蛋白表达、流式、体外杀伤和小鼠模型验证。
真正的新意是 AI 改了靶点排序这一步
这篇的 AI 新意不在于生成 CAR 结构,也不在于预测患者疗效,而在于把“专家如何权衡靶点好坏”做成一个可重复的排序流程。作者先构建皮肤癌与正常皮肤的单细胞 atlas,再为每个候选基因补充细胞表面定位、正常组织表达、临床可开发性和肿瘤组成等特征。
随后,三类 LLM 被用来做两件事:第一,帮助评估这些特征的权重;第二,从 top-100 候选中反复提名最值得推进的靶点,并给出理由。GPNMB 成为最频繁被提名的候选,然后才进入传统的生物学验证链路。
所以这不是“AI 直接证明 GPNMB CAR-T 有效”,而是“AI 把一个原本高度依赖专家经验和分散数据库检索的筛靶过程,变成了可记录、可重复、可外部验证的候选排序机制”。
证据强在 AI 提名后接上了湿实验闭环
这篇最强的证据形态,是从 top-100 候选排序接到正交湿实验和三种小鼠模型。计算端,作者使用 GPT-4o、Claude-3.7 和 Gemini-2.5 Pro,每个模型 1,000 次模拟,从 100 个候选基因中提名靶点;GPNMB 是最频繁被提名的候选,且在额外重复后显示一定稳定性。对照也有价值:去掉专家权重后,top-100 有 94 个重合、top-15 有 12 个重合;但把输入从单细胞换成 bulk RNA-seq 后,top-100 只重合 21 个、top-15 只重合 2 个,说明 AI 排序高度依赖输入数据分辨率。
实验端,作者用 TCGA/GTEx、IHC、免疫荧光和非透化流式验证 GPNMB 及其他候选靶点的表达和表面定位;在 4 个 melanoma 细胞系中验证多个候选靶点的表面表达。随后他们构建了 GPNMB CAR T,在体外看到对 GPNMB 阳性的 ML/AML 和多种实体瘤细胞杀伤,并保留了 GPNMB 阴性的 B-ALL 作为负向对照。体内部分包括 monoblastic leukemia、melanoma 和 colorectal adenocarcinoma 三类免疫缺陷小鼠 xenograft 模型:ML 模型为 n=15 CAR T 对 n=14 control,melanoma 与 colorectal 模型均为 n=16 CAR T 对 n=14 control;colorectal 模型中 CAR T 组全部完全缓解,melanoma 模型多数完全缓解但有少数复发。
别误读第一点:这不是临床有效性证明,也不是多癌种疗法已经成熟。别误读第二点:LLM 提名稳定、体外杀伤和 xenograft 有效,都不能等同人体安全;作者也明确指出该 CAR 不识别小鼠 GPNMB,因此小鼠实验无法直接测试人类正常组织中的 on-target/off-tumor 毒性。
最重要的一点:杠杆在筛选,卡点在安全闭环
这篇给 AI 生物医药应用边界的核心判断很清楚:AI 的真实杠杆在候选靶点 triage,而不是在最终疗法证明。把分散证据整合后交给 LLM 反复权衡,可以显著降低“先看哪一个靶点”的决策成本,也能把专家经验变成更透明的排序过程。
但真正昂贵的卡点没有消失。CAR-T 靶点的成败最终取决于人类正常组织安全性、抗原异质性、肿瘤微环境、T 细胞扩增/持久性和临床剂量窗口。尤其是 GPNMB 这种跨癌种表达的抗原,覆盖面越广,越需要非常严肃地证明正常组织风险可控。
这正好呼应 AI 落地的一条尺子:当答案能用相对便宜的湿实验验证时,AI 可以很快把候选收窄;当验证变成长期人体安全性和真实疗效时,落地速度仍由临床闭环决定。
批判性阅读:别把 LLM 排名当成临床成熟
第一条红旗是泛化。发现流程从皮肤癌单细胞 atlas 出发,后续确实验证了 GPNMB 在多癌种中的表达和功能,但“从 melanoma 起步”到“多癌种适用”之间仍需要更多独立肿瘤、更多患者样本和更贴近人体免疫环境的模型。
第二条红旗是可复现性。论文提供了 Zenodo 数据和 GitHub 代码,这比纯黑箱 AI 论文强;但 LLM 排名使用商业模型、温度采样和模型快照,外部团队需要确认在不同时间、不同模型版本、不同候选池下是否还能稳定得到相近结果。
第三条红旗是数据泄漏与“已知知识再排序”。GPNMB 本来就有抗体药物偶联物 glembatumumab vedotin 的临床开发历史,说明它不是完全从零发现的新靶点。AI 可能真正做的是把已有证据重新权衡和排序,这依然有价值,但不能写成模型凭空发现了一个全新生物学对象。
第四条红旗是公平 baseline。最有说服力的未来验证不是再展示 LLM 能讲出合理理由,而是做前瞻性盲评:同一批候选靶点中,AI 排序是否比专家手工筛选、数据库规则筛选或传统加权模型更快找到可验证靶点。
第五条红旗是安全性。免疫缺陷小鼠 xenograft 可以证明抗肿瘤活性,却不能证明人类正常组织安全。论文也提到,既往 GPNMB 抗体药物偶联物的 phase 2b 研究没有达到主要终点;CAR-T potency 更强,既可能带来疗效,也可能放大安全风险。
对 AI 应用边界的启发
投资 / 合作判断上,这篇提醒我看 AI drug discovery 公司时要问一个更具体的问题:它是否把验证成本降下来了?如果平台只是生成更多候选,却没有可执行的 wet-lab loop、负例记录、正常组织安全验证和外部可复现路径,商业价值会很容易停在 demo。
科研方向跟踪上,我会继续看三类证据:第一,类似 target-triage pipeline 能否在别的癌种、别的免疫治疗靶点上前瞻性复现;第二,GPNMB CAR T 的早期临床安全信号是否支持继续推进;第三,AI 排序是否真的比专家加权和传统规则筛选更省实验。
待解问题有两个:GPNMB 在真实患者正常组织中的安全窗口到底有多宽?以及,LLM 在这种流程里贡献的是独立推理,还是把已有公共知识和专家偏好更高效地重新排列?
Yang 的信号评级:High
轴一,信号强度:High。理由:这篇不是停在 in-silico 排名,而是把 AI 靶点提名接到了 IHC、流式、体外杀伤和三个 xenograft 模型;GPNMB 作为候选靶点有跨癌种表达、已有结合域和可见的临床转化路径。
轴二,技术/落地成熟度:Medium。理由:作为 target-triage 和临床前验证流程,它已经相当成熟;作为多癌种 CAR-T 疗法,还处在早期,因为人类安全性、on-target/off-tumor 风险、真实肿瘤微环境和临床疗效都需要更昂贵的验证。
一句话总结:这篇说明 AI 在 CAR-T 里最先有用的地方,是把靶点候选快速排队;真正决定能否落地的,仍是生物安全性和临床验证。
Teams from the University of Pennsylvania, RWTH Aachen, Icahn School of Medicine at Mount Sinai and collaborators recently reported an AI-driven CAR T target discovery workflow in Cell, then advanced GPNMB into preclinical GPNMB CAR T validation. The paper is worth reading not because an LLM directly invented a therapy, but because it puts AI in a target-discovery step where evidence is fragmented and validation is expensive. It shows one realistic use of AI in biomedicine: reduce candidate-ranking cost first, then close the loop with wet-lab validation.
Why CAR T target discovery invites AI
The real bottleneck is not whether another CAR T construct can be built. It is the scarcity of safe targets. An ideal CAR T antigen needs high tumor expression, low expression in vital normal tissues, cell-surface localization, antibody or clinical tractability and, ideally, coverage across enough patients. That evidence is scattered across single-cell datasets, GTEx, HPA, UniProt, Open Targets, ClinicalTrials.gov and protein-expression databases.
The primary reason for AI intervention is fragmented evidence. Secondary reasons are a large search space and slow experimental validation. The value-chain position is target discovery through preclinical validation: integrate data and use LLM reasoning to narrow the candidate space, then hand a small set of targets to protein expression, flow cytometry, in vitro killing and mouse-model validation.
What is new is the target-ranking step
The AI contribution is not CAR-structure generation or patient-response prediction. It is a reproducible way to model how experts weigh target quality. The authors first built a single-cell atlas of skin cancer and healthy skin, then augmented each candidate gene with features such as surface localization, normal-tissue expression, clinical tractability and tumor composition.
Three LLM families were then used for two tasks: first, to help assess feature weights; second, to repeatedly nominate the most promising targets from a top-100 candidate list and explain the reasons. GPNMB became the most frequently nominated candidate and was then taken into conventional biological validation.
So the contribution is not “AI proved GPNMB CAR T works.” It is that AI turned a target-screening process that usually relies on expert intuition and fragmented database searches into a logged, repeatable and externally testable candidate-ranking mechanism.
The evidence is strong because AI nomination was followed by wet-lab closure
The strongest evidence shape is a top-100 computational shortlist followed by orthogonal wet-lab validation and three mouse models. On the computational side, the authors used GPT-4o, Claude-3.7 and Gemini-2.5 Pro, with 1,000 simulations per model, to nominate targets from 100 candidate genes. GPNMB was the most frequently nominated candidate, and additional reruns showed stability. The controls are informative: without expert-defined weights, 94 of the top 100 and 12 of the top 15 candidates overlapped; but replacing single-cell input with bulk RNA-seq led to only 21 of the top 100 and 2 of the top 15 overlapping, showing that AI ranking depends heavily on input resolution.
Experimentally, the authors used TCGA/GTEx, IHC, immunofluorescence and non-permeabilized flow cytometry to validate expression and surface localization of GPNMB and other candidates. They confirmed surface expression of several candidates across four melanoma cell lines. They then built a GPNMB CAR T, observed in vitro killing of GPNMB-positive ML/AML and multiple solid-tumor cells, and retained GPNMB-negative B-ALL as a negative control. In vivo, the study used monoblastic leukemia, melanoma and colorectal adenocarcinoma immunodeficient xenograft models: n=15 CAR T versus n=14 control in the ML model, and n=16 CAR T versus n=14 control in both melanoma and colorectal models. The colorectal CAR T group showed complete remission in all mice, while the melanoma group showed complete remission in most mice but a small number of relapses.
Do not misread this in two ways. First, this is not clinical efficacy proof, and it does not mean a multi-cancer therapy is mature. Second, stable LLM nomination, in vitro killing and xenograft efficacy do not equal human safety. The authors explicitly note that this CAR does not recognize murine GPNMB, so the mouse studies cannot directly test on-target/off-tumor toxicity in human normal tissues.
The leverage is triage; the bottleneck is safety closure
The key boundary judgment is clear: AI’s real leverage is candidate-target triage, not final therapeutic proof. Once fragmented evidence is integrated and repeatedly weighed by LLMs, the system can lower the cost of deciding which target to test first and make expert trade-offs more transparent.
But the expensive bottleneck remains. CAR T target success ultimately depends on normal-tissue safety, antigen heterogeneity, tumor microenvironment, T cell expansion and persistence, and the clinical dose window. For an antigen such as GPNMB, whose appeal comes partly from broad cross-cancer expression, breadth makes safety proof even more important.
This maps directly onto the validation-cost rule for AI in biomedicine: when answers can be checked by relatively affordable wet-lab assays, AI can narrow candidates quickly; when validation becomes long-horizon human safety and real efficacy, clinical closure still sets the speed limit.
Read it critically: do not mistake LLM ranking for clinical maturity
The first red flag is generalization. The discovery workflow starts from a skin-cancer single-cell atlas. The authors do validate GPNMB expression and function across multiple cancers, but moving from melanoma-centered discovery to multi-cancer applicability still requires more independent tumors, more patient samples and models closer to human immune biology.
The second red flag is reproducibility. The paper provides Zenodo data and GitHub code, which makes it stronger than a black-box AI study. But the LLM ranking step uses commercial models, sampling temperatures and model snapshots. External groups need to test whether similar rankings hold across time, model versions and candidate pools.
The third red flag is data leakage and re-ranking known knowledge. GPNMB already had a clinical-development history through the antibody-drug conjugate glembatumumab vedotin, so this is not a target discovered from nothing. AI may be doing something valuable but narrower: reweighing and ranking existing evidence more efficiently.
The fourth red flag is the baseline. The most convincing future test would not be another set of plausible LLM explanations. It would be a prospective blinded comparison showing whether AI ranking beats expert manual screening, database-rule screening or traditional weighted models in finding experimentally valid targets faster.
The fifth red flag is safety. Immunodeficient xenograft models can show anti-tumor activity, but they cannot prove human normal-tissue safety. The paper also notes that a prior GPNMB antibody-drug conjugate phase 2b trial failed to meet its primary endpoint. CAR T potency could improve efficacy, but it could also amplify risk.
What this implies for AI application boundaries
For investment or collaboration judgment, the paper suggests asking a sharper question about AI drug-discovery platforms: did the platform lower validation cost? If a company only generates more candidates, but lacks an executable wet-lab loop, negative-case tracking, normal-tissue safety testing and external reproducibility, its value can remain demo-level.
For research tracking, I would follow three evidence streams: whether similar target-triage pipelines prospectively reproduce in other cancers and immunotherapy target classes; whether early clinical safety signals for GPNMB CAR T support continued development; and whether AI ranking truly saves experiments compared with expert weighting and traditional rule-based screening.
Two open questions matter. How wide is the real safety window for GPNMB in human normal tissues? And in this workflow, is the LLM contributing independent reasoning, or mostly rearranging public knowledge and expert priors more efficiently?
Yang’s signal rating: High
Axis one, signal strength: High. Reason: this study does not stop at in-silico ranking. It connects AI target nomination to IHC, flow cytometry, in vitro killing and three xenograft models. GPNMB also has cross-cancer expression, available binding domains and a visible translational path.
Axis two, technical / deployment maturity: Medium. Reason: as a target-triage and preclinical validation workflow, it is fairly mature. As a multi-cancer CAR T therapy, it remains early because human safety, on-target/off-tumor risk, real tumor microenvironment effects and clinical efficacy require much more expensive validation.
One-sentence summary: This paper shows that AI’s first practical role in CAR T is to rank target candidates faster; biological safety and clinical validation still decide whether the idea can land.