SEED AI | MRAI:临床推理 AI 慢在验证,不慢在模型 SEED AI | MRAI is slowed by validation, not only by models AI-assisted · reviewed
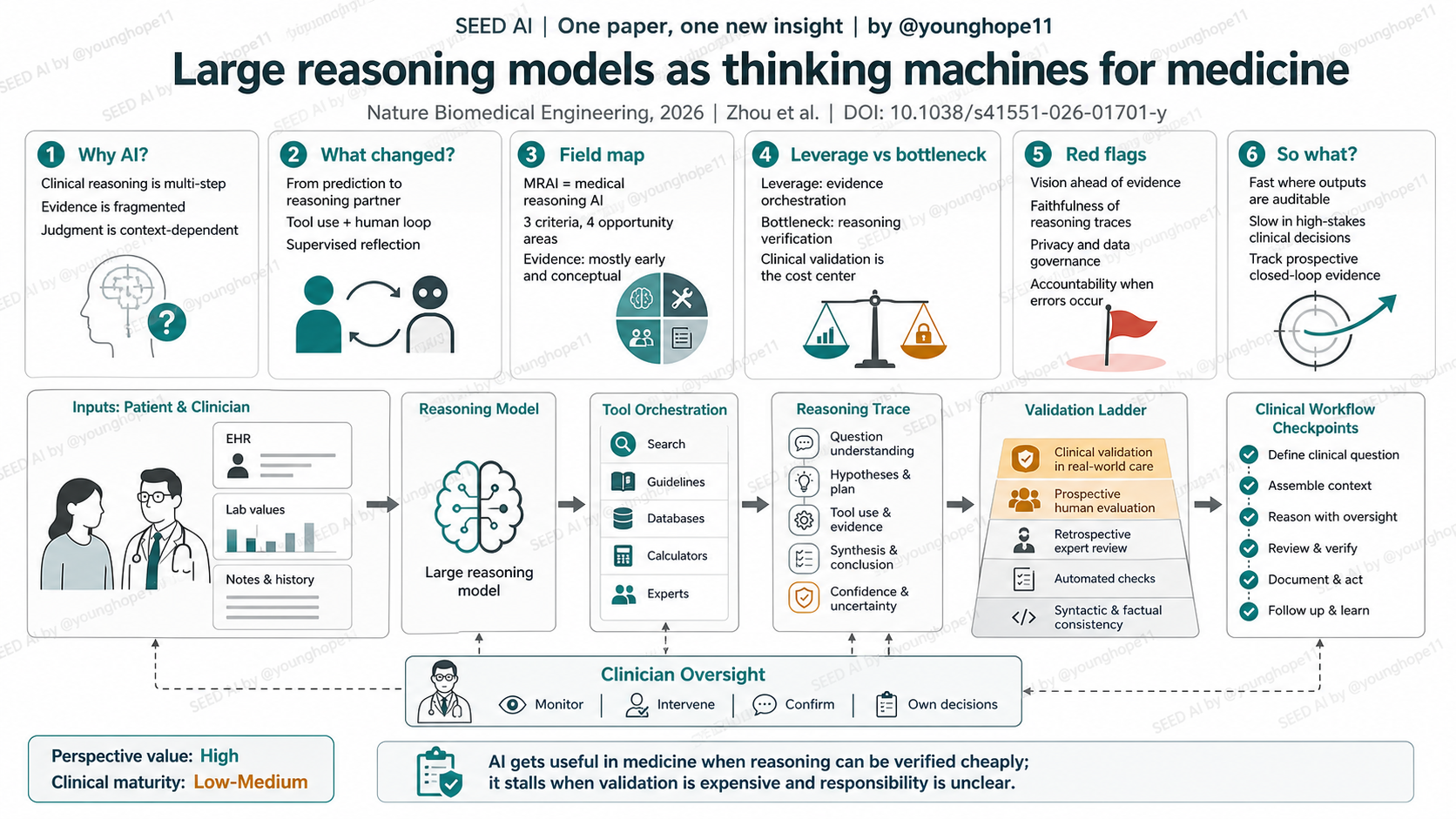
Hong-Yu Zhou、Adam Rodman、Pranav Rajpurkar、Eric Topol 等人近期在 Nature Biomedical Engineering 发表 Perspective,提出 medical reasoning artificial intelligence(MRAI)这个框架,讨论大推理模型如何从“预测工具”走向医疗里的“推理伙伴”。这篇文章值得读,不是因为它报告了新的临床试验结果,而是因为它把临床 AI 的核心问题重新放到验证成本上:模型会推理只是起点,真正的问题是推理链能不能被医生低成本核验,并被医疗系统治理。
为什么临床推理会被 AI 介入
临床推理适合被 AI 介入,不是因为医生缺少一个“答案生成器”,而是因为真实医疗决策同时面对证据碎片化、数据源复杂、时间压力和判断主观性。一个复杂病例往往需要整合病史、影像、检验、指南、药物相互作用、基因信息和患者偏好,单一预测模型很难覆盖这种动态过程。
这篇文章的主瓶颈是“证据太碎”,次瓶颈是“人工判断太主观”和“临床验证太慢”。AI 进入的位置不是靶点发现或分子设计,而是价值链末端的临床决策 / 落地:它试图把多源信息整合、假设生成、诊疗计划和反馈学习组织成可审计的推理流程。
真正的新意是把 AI 从预测器改成推理工作流
文章的新意不在于提出一个新模型指标,而在于把医疗 AI 的目标从“给出分类或风险分数”改成“组织推理过程”。作者定义的 MRAI 有三条标准:持续 human-in-the-loop 互动,多工具和多数据源编排,以及受监督的反思与适应。
这一步改变的是临床 AI 的价值链位置。传统医疗 AI 多数是局部任务工具,例如看一张影像、预测一个风险、回答一个问题;MRAI 设想的是在医生和患者之间运行的推理系统,可以调用 EHR、实验室系统、医学数据库、指南和计算工具,并在医生监督下反思以往决策。
关键边界也在这里:这不是“自动医生”。如果没有医生审核、患者语境、工具授权和责任框架,所谓推理伙伴很容易退化成更会写解释的聊天机器人。
领域地图强,直接证据仍早
这篇 Perspective 的证据形态不是实验结果表,而是领域地图和核心主张。作者把 MRAI 拆成三类能力,连接到四类机会:改善医患互动、可审计诊断、个体化治疗规划,以及药物发现与开发;再把技术路线分成 post-training、prompt optimization 和 agentic modelling。
证据分层上,最扎实的是组件级趋势:医学 LLM、诊断 benchmark、agentic tool use、prompt optimization、retrieval-augmented systems 和近年的 conversational diagnostic AI 都在说明“推理式医疗 AI”正在变得可行。弱一层的是系统级证据:文章自己也承认,目前还没有完整 MRAI 系统真正进入临床实践。
别误读第一点:这不是一篇证明 MRAI 已经可临床部署的论文,而是一篇定义框架和验证路线的 Perspective。别误读第二点:模型能输出一条看似合理的 reasoning trace,不等于这条 trace 就忠实代表模型内部因果过程,更不等于医生可以跳过核验。
最重要的一点:杠杆在证据编排,卡点在推理验证
这篇文章最重要的判断是:AI 在医疗里的真实杠杆,不是替医生“想得更神”,而是把分散证据、工具调用和中间推理步骤组织成医生能检查的结构。这个方向如果成功,AI 可以减少信息遗漏、改善复杂病例的证据整合,并让医学教育和治疗规划更动态。
但瓶颈同样清楚:临床推理的验证成本极高。一个肺结节 AI 告诉医生“有 87% 概率”,医生可以快速看图确认;一个 MRAI 给出多步鉴别诊断、药物选择和治疗计划,医生必须逐步核对逻辑、证据和责任。推理越复杂,越可能把省下的信息搜索时间还给 verification burden。
所以这篇文章强化了一个贯穿判断:AI 在答案便宜、客观、可快速验证的地方落地快;在临床推理这种验证昂贵、责任复杂、结果长周期的地方,模型能力提升不等于落地成熟。
批判性阅读:愿景、trace 和责任框架
第一条红旗是愿景是否跑在证据前。作者没有利益冲突声明,这降低了“公司宣传稿式综述”的风险,但文章整体仍是框架和愿景,读的时候不能把“应该如何验证”误读成“已经通过验证”。
第二条红旗是 reasoning trace 的可信度。临床 AI 最诱人的地方是可解释推理,但语言模型生成的 step-by-step 解释可能只是事后合理化。未来真正重要的不是解释看起来像医生,而是推理步骤能否被外部证据、规则、指南和临床结局逐项验证。
第三条红旗是 workflow cost。MRAI 可能让医生多花时间审核推理链,尤其在急诊、影像和高通量场景里,验证疲劳本身会成为安全风险。
第四条红旗是隐私、偏差和责任归属。MRAI 需要跨 EHR、影像、检验、基因、文献和指南整合信息,一旦出错,责任不再只是“医生有没有看 AI 提示”,而是要追问每个推理步骤、数据来源、工具调用和机构治理是否合理。
对 AI 应用边界的启发
投资 / 合作判断上,应该更重视能构建验证闭环的团队,而不是只看模型演示。值得跟踪的不是谁能做最漂亮的临床对话 demo,而是谁能接入真实工作流、定义客观 endpoint、记录推理 trace、让医生高效审核,并把责任和合规边界设计清楚。
科研方向跟踪上,我会关注三类证据:第一,reasoning trace faithfulness 的验证方法;第二,从 retrospective benchmark 走向 prospective clinical workflow 的研究;第三,人机协作到底是降低医生负担,还是把负担转移到更隐蔽的审核环节。
待解问题有两个:MRAI 的推理链能否被设计成“局部可验证”,让医生只核查关键节点而不是整条长链?以及,在不同科室和风险等级里,哪些任务的验证成本足够低,能成为临床推理 AI 的第一批真实落地点?
Yang 的信号评级:High
轴一,视角价值:High。理由:这篇文章给出了一个清晰的临床推理 AI 框架,把 human-in-the-loop、tool orchestration 和 supervised reflection 放在同一张图里,也把验证、治理、责任和工作流成本明确列为核心约束。
轴二,临床成熟度:Low-Medium。理由:组件证据正在变强,但完整 MRAI 仍主要停留在框架与早期 proof-of-concept,真正的前瞻性临床验证、监管路径、责任归属和工作流 ROI 还没有闭合。
一句话总结:MRAI 的价值不在于让 AI 像医生一样“想”,而在于让复杂医学推理变成可检查、可追责、可逐步验证的工作流。
Hong-Yu Zhou, Adam Rodman, Pranav Rajpurkar, Eric Topol and colleagues recently published a Perspective in Nature Biomedical Engineering that proposes medical reasoning artificial intelligence, or MRAI, as a framework for moving large reasoning models from prediction tools toward reasoning partners in medicine. The paper is worth reading not because it reports a new clinical trial, but because it reframes the clinical AI question around validation cost: reasoning ability is only the beginning; the hard part is whether clinicians can verify, govern and take responsibility for the reasoning process.
Why clinical reasoning invites AI
Clinical reasoning invites AI not because physicians need another answer generator, but because real medical decisions involve fragmented evidence, complex data sources, time pressure and context-dependent judgment. A difficult case may require integrating history, imaging, laboratory results, guidelines, drug interactions, genomic data and patient preferences. A narrow prediction model cannot easily cover that dynamic process.
The primary bottleneck here is fragmented evidence. Secondary bottlenecks are subjective human judgment and slow clinical validation. AI enters at the clinical decision and deployment end of the value chain, not at target discovery or molecular design: the ambition is to organize information integration, hypothesis generation, care planning and feedback into an auditable reasoning workflow.
What changed is the workflow, not a single score
The novelty is not a new model metric. It is a shift in the goal of medical AI: from providing classifications or risk scores to organizing the reasoning process. The authors define MRAI with three criteria: continuous human-in-the-loop interaction, orchestration of multiple tools and data sources, and supervised reflection and adaptation.
That changes the position of clinical AI in the value chain. Traditional medical AI is often a local task tool: reading one image, predicting one risk or answering one question. MRAI imagines a reasoning system operating between clinicians and patients, calling electronic health records, laboratory systems, medical databases, guidelines and computational tools, while reflecting on previous decisions under clinical supervision.
The boundary is just as important: this is not an autonomous doctor. Without clinician review, patient context, tool authorization and accountability structures, a reasoning partner can quickly become a chatbot that writes better explanations.
The field map is strong, but direct evidence is early
The evidence shape of this Perspective is not a results table. It is a field map and core claim. The authors organize MRAI into three capabilities and connect them to four opportunity areas: clinician-patient connection, auditable diagnostics, personalized treatment planning, and drug discovery and development. They then map the technical path through post-training, prompt optimization and agentic modelling.
The strongest evidence layer is component-level momentum: medical LLMs, diagnostic benchmarks, agentic tool use, prompt optimization, retrieval-augmented systems and recent conversational diagnostic AI all suggest that reasoning-oriented medical AI is becoming feasible. The weaker layer is system-level evidence. The authors explicitly note that no comprehensive MRAI system is in clinical practice.
Do not misread this in two ways. First, this is not evidence that MRAI is clinically deployable today; it is a framework for what would have to be built and validated. Second, a model that outputs a plausible reasoning trace has not proven that the trace faithfully represents its internal causal process, and it certainly does not let clinicians skip verification.
The leverage is evidence orchestration; the bottleneck is verification
The paper’s most important judgment is that the real leverage of AI in medicine is not replacing physicians with stronger reasoning, but organizing scattered evidence, tool calls and intermediate inferences into a structure clinicians can inspect. If that works, AI could reduce missed information, improve complex-case evidence integration and make education or treatment planning more adaptive.
The bottleneck is equally clear: clinical reasoning is expensive to verify. If an imaging AI says a lung nodule is likely present, a clinician can often inspect the image quickly. If MRAI generates a multi-step differential diagnosis, treatment plan and drug-selection rationale, the clinician must check the logic, evidence and responsibility step by step. As reasoning becomes more complex, the time saved on information search may reappear as verification burden.
This strengthens a broader boundary rule: AI moves faster where outputs are cheap, objective and quick to test. In clinical reasoning, where validation is expensive, accountability is complex and outcomes can be long-horizon, model improvement does not equal deployment maturity.
Read it critically: vision, traces and accountability
The first red flag is whether the vision runs ahead of evidence. The authors declare no competing interests, which lowers the risk of a company-promotional review, but the article is still a framework and vision piece. It should not be read as evidence that MRAI has already passed clinical validation.
The second red flag is reasoning-trace faithfulness. The promise of clinical AI is auditable reasoning, but step-by-step explanations from language models can be post hoc rationalizations. The important question is not whether the explanation sounds clinician-like, but whether each reasoning step can be checked against external evidence, rules, guidelines and patient outcomes.
The third red flag is workflow cost. MRAI may require clinicians to spend extra time reviewing reasoning chains, especially in emergency, radiology or other high-throughput settings. Verification fatigue could itself become a safety risk.
The fourth red flag is privacy, bias and responsibility. MRAI would integrate information across EHRs, imaging, labs, genomics, literature and guidelines. When it fails, the accountability question is no longer simply whether a clinician reviewed an AI alert; it becomes whether each reasoning step, data source, tool call and institutional control was appropriate.
What this implies for AI application boundaries
For investment or collaboration judgment, the signal is to value teams that can build validation loops rather than teams with impressive demos only. The stronger partner is not necessarily the one with the smoothest clinical chatbot, but the one that can enter real workflows, define objective endpoints, record reasoning traces, let clinicians review efficiently and design clear compliance and liability boundaries.
For research tracking, I would follow three evidence streams: methods for reasoning-trace faithfulness, studies moving from retrospective benchmarks into prospective clinical workflows, and evidence on whether human-AI collaboration actually lowers clinician burden or simply moves the burden into hidden review work.
Two open questions matter most. Can MRAI reasoning chains be designed for local verification, so clinicians check key nodes instead of a long chain? And across specialties and risk levels, which tasks have low enough validation cost to become the first real landing points for clinical reasoning AI?
Yang’s signal rating: High
Axis one, perspective value: High. Reason: the article gives a clear framework for clinical reasoning AI, placing human-in-the-loop interaction, tool orchestration and supervised reflection in one architecture while making validation, governance, accountability and workflow cost central constraints.
Axis two, clinical maturity: Low-Medium. Reason: component evidence is strengthening, but full MRAI remains largely a framework and early proof-of-concept direction. Prospective clinical validation, regulatory pathways, accountability and workflow return on investment are not yet closed.
One-sentence summary: MRAI matters not because AI can think like a doctor, but because complex medical reasoning may become checkable, accountable and incrementally verifiable.