SEED AI | OpenIO:AI 免疫治疗先要补验证底座 SEED AI | OpenIO shows AI-native immunotherapy needs a validation base first AI-assisted · reviewed
Fudan University、Shanghai Jiao Tong University、Princeton、Westlake University 等团队近期在 Cancer Cell 发表 Commentary,提出 Open Immune Oncology(OpenIO)作为 AI-native immunotherapy 的开放框架。这篇文章的价值不在于报告新实验,而在于把免疫治疗从“经验筛选”推向“数据标准化、基础模型、生成式设计、闭环验证、临床模拟”的整体路线图;它同时也暴露了一个关键边界:AI 可以先帮我们组织免疫治疗的工程系统,但真正慢的仍是可复现验证和临床闭环。
为什么免疫治疗需要 AI 原生框架
这篇论文真正面对的不是“再做一个免疫治疗模型”,而是免疫治疗长期卡在高维、非线性、强个体差异和验证昂贵上。ICI、CAR-T、TCR-T、细胞因子和抗体治疗都牵涉肿瘤细胞、免疫细胞、抗原呈递、空间微环境、时间动态和毒性窗口;传统线性 biomarker 很难捕捉这种上下文依赖。
AI 介入的主因是证据太碎、预测建模太难,次因是实验太慢。价值链位置横跨 basic understanding / modeling、target discovery、design、preclinical、clinical trial design 和 clinical decision simulation。OpenIO 的主张是:如果能把多中心队列、组学、免疫表型、临床轨迹和实验反馈标准化,免疫治疗就可能从 retrospective analysis 走向 predictive and generative modeling。
真正的新意是把免疫治疗写成一套工程系统
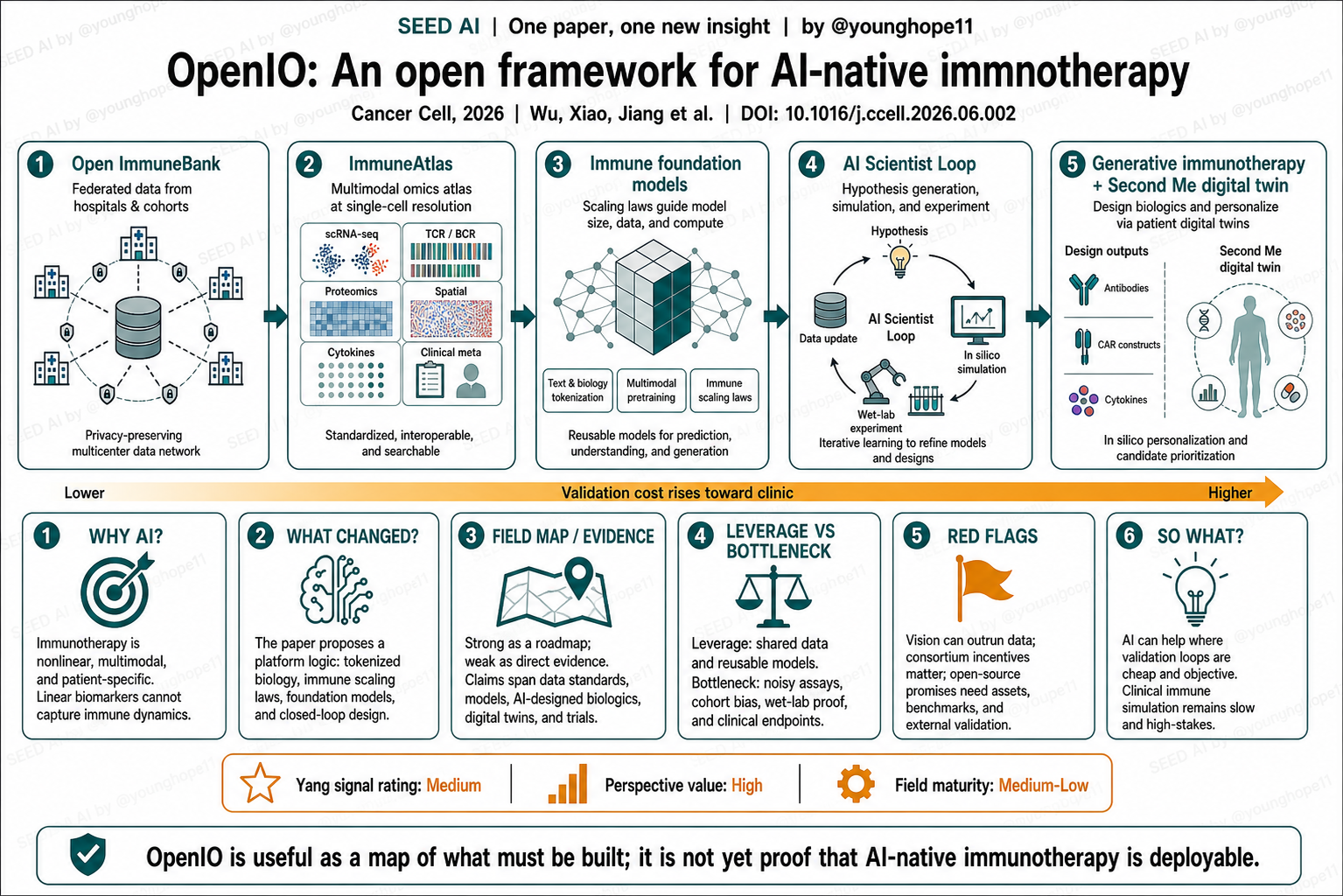
OpenIO 改变的不是某一个生物结论,而是提出一个“平台逻辑”。它把 biology tokenization、immune scaling laws、ImmuneBank、ImmuneAtlas、immune foundation models、AI Scientist loop、generative immunotherapy 和 Second Me 数字免疫孪生串成一条链。
这条链的非显然之处在于,它没有把 AI 局限在单点任务上,例如只预测 MHC binding 或只优化抗体亲和力,而是试图让数据标准、模型预训练、生成式设计、自动化实验和临床模拟互相喂数据。换句话说,AI 改的不是某个末端模型,而是免疫治疗研发价值链里的“可计算基础设施”。
但这也意味着它更像 roadmap,而不是已经完成的产品。OpenIO 现在的核心贡献是把未来 2026-2028 年想做的关键模块摆出来,让读者能判断哪些模块已经接近可验证,哪些仍停留在愿景层。
领域地图、核心主张与证据分层
这篇最强的证据形态不是实验数据,而是 field map。OpenIO 把 AI-native immunotherapy 拆成五层:第一,多中心患者队列和 federated ImmuneBank;第二,标准化、可搜索的 multimodal ImmuneAtlas;第三,免疫语言模型、抗原呈递模型和 TME world model;第四,AI Scientist loop,把假设生成、模拟、机器人湿实验和模型更新接成闭环;第五,生成式免疫治疗和 Second Me 数字免疫孪生。
证据分层需要分清。比较扎实的是已有相邻技术:scGPT、Evo、virtual cell、IgLM、HLAPollo、LUMI-lab、自驱动实验室和免疫治疗预测模型等,说明 AI-for-biology 的组件正在出现。中等证据是 OpenIO 明确提出了数据标准、开放 benchmark、开源 biologics 和 federated learning nodes 等可检验承诺。最弱、最需要打折的是愿景层:immune scaling laws 是否成立、10^8-10^9 cells 是否带来可迁移能力、Generative Yield 能否从当前小于 1% 提升、2027 年 first-in-human fully AI-designed biologics 和 2028 年数字孪生临床报告能否落地,都还需要未来证据。
所以别误读第一点:这不是新疗法已经被 AI 设计并验证。别误读第二点:数字免疫孪生不是临床标准工具,作者自己也说时间线应理解为 aspirational goals,而不是 definitive predictions。
最重要的一点:杠杆在共享底座,卡点在验证成本
OpenIO 对 AI 应用边界最有用的判断是:AI-native immunotherapy 的杠杆不只是模型,而是 shared data + shared benchmarks + shared reagents + closed-loop labs。免疫治疗的问题太复杂,如果每个团队都用不兼容的数据、试剂、指标和验证方法,基础模型很容易学到 batch effect、队列偏差或实验噪声。
真正卡住的地方也很清楚:免疫数据不是文本。文本 token 可以大规模复制,免疫数据却受样本处理、抗体批次、测序平台、组织来源、治疗时点、种族和性别构成影响。模型在 in silico 上给出治疗建议,不等于它能预测 cytokine storm、T cell exhaustion、on-target/off-tumor toxicity 或长期生存终点。
这篇再次印证 AI 生物医药的一条尺子:越靠近可重复、低成本、客观评价的环节,AI 越容易落地;越靠近临床决策、毒性、责任归属和长期终点,AI 越需要严密的人类验证体系。
批判性阅读:愿景、利益冲突和开放承诺
第一条红旗是 vision outruns evidence。OpenIO 的图景很完整,但大部分关键模块还在规划或引用相邻案例,不能把路线图当成完成态平台。尤其是 Second Me 数字免疫孪生和自主免疫治疗实验室,如果没有前瞻性、外部验证和真实临床 endpoint,很容易变成漂亮概念。
第二条红旗是利益冲突和生态激励。声明中提到一位作者来自 ByteDance Seed,另一位作者是 Neolife AI 创始人;这并不否定文章价值,但读者应把它看成带有产业生态建设意图的 Commentary,而不是中立系统综述。
第三条红旗是开放承诺能否兑现。文章说 OpenIO 将释放非专利免疫学资产、开放抗体序列、诊断抗体、标准协议、benchmark 和模型。如果这些资源没有可下载版本、许可、版本管理、外部复现实验和失败案例记录,“open-source immunotherapy”就会停留在口号层。
第四条红旗是数据治理。Federated learning 可以缓解隐私问题,但不能自动解决 cohort bias、assay drift、医院间标准不一致和少数族群代表性不足。免疫 foundation model 的可靠性,最终取决于数据能否被标准化、审计和持续更新。
第五条红旗是临床责任。数字孪生如果参与治疗选择,错了谁负责?模型开发者、医院、医生、试剂供应方、还是数据提供者?这类问题不解决,AI clinical simulation 很难从研究工具变成可部署工具。
对 AI 应用边界的启发
投资 / 合作判断上,OpenIO 给出一个检查清单:有没有真实多中心数据网络?有没有标准化样本和试剂?有没有开放 benchmark?有没有 wet-lab loop?有没有失败数据?有没有临床 endpoint 和监管路径?只讲 foundation model 或 digital twin,而没有这些底座,商业成熟度就很低。
科研方向跟踪上,我会关注三件事:第一,OpenIO 是否如期发布可用数据、模型、benchmark 和实验资产;第二,immune scaling law 是否能被控制实验验证;第三,Second Me 这类数字免疫孪生能否先在低风险任务中证明价值,例如患者分层、试验设计或毒性风险排序,而不是直接指导治疗。
待解问题有两个:免疫系统是否真的存在可工程化的 scaling law?以及,AI 生成的免疫治疗候选物,究竟能不能把验证成本从“临床碰运气”前移到便宜、客观、可重复的实验闭环?
Yang 的信号评级:Medium
轴一,视角价值:High。理由:OpenIO 把 AI-native immunotherapy 所需的数据、模型、实验闭环、开放生态和临床模拟放到同一张图里,对判断领域路线非常有价值。
轴二,领域成熟度:Medium-Low。理由:相邻技术已经存在,但 OpenIO 本身大多仍是路线图;真正昂贵的部分是数据标准化、实验复现、first-in-human 验证、临床 endpoint 和责任边界。
一句话总结:OpenIO 最有用的地方,是告诉我们 AI 免疫治疗要先补什么底座;它还不是 AI 免疫治疗已经可部署的证据。
Teams from Fudan University, Shanghai Jiao Tong University, Princeton, Westlake University and collaborators recently published a Cancer Cell Commentary proposing Open Immune Oncology, or OpenIO, as an open framework for AI-native immunotherapy. Its value is not a new experiment. It is a roadmap that places immunotherapy on a shared path from data standardization to foundation models, generative design, closed-loop validation and clinical simulation. It also exposes a key boundary: AI can help organize the engineering system for immunotherapy, but reproducible validation and clinical closure remain the slow steps.
Why immunotherapy needs an AI-native framework
The bottleneck here is not another standalone immunotherapy model. Immunotherapy is constrained by high dimensionality, nonlinearity, patient specificity and expensive validation. ICIs, CAR T, TCR T, cytokines and antibody therapies all involve tumor cells, immune cells, antigen presentation, spatial microenvironment, temporal dynamics and toxicity windows. Traditional linear biomarkers often fail to capture this context dependence.
The primary reasons for AI intervention are fragmented evidence and difficult prediction. A secondary reason is slow experimentation. The value-chain position spans basic understanding and modelling, target discovery, design, preclinical validation, clinical-trial design and clinical decision simulation. OpenIO argues that if multicenter cohorts, omics, immune phenotypes, clinical trajectories and experimental feedback can be standardized, immunotherapy may move from retrospective analysis toward predictive and generative modelling.
What changed is the engineering logic for the field
OpenIO does not change one biological conclusion. It proposes a platform logic that connects biology tokenization, immune scaling laws, ImmuneBank, ImmuneAtlas, immune foundation models, an AI Scientist loop, generative immunotherapy and the Second Me digital immune twin.
The non-obvious move is that it does not confine AI to a single task, such as MHC binding prediction or antibody-affinity optimization. It tries to make data standards, pretraining, generative design, automated experiments and clinical simulation feed one another. In other words, AI is not merely another endpoint model here. It is proposed as computable infrastructure for the immunotherapy value chain.
That also means the paper is a roadmap, not a finished product. Its main contribution is to lay out the modules that OpenIO wants to build across 2026-2028, so readers can separate what is already close to verifiable from what remains aspirational.
Field map, core claim and evidence stratification
The strongest evidence shape is a field map rather than experimental data. OpenIO divides AI-native immunotherapy into five layers: multicenter cohorts and a federated ImmuneBank; a standardized, searchable multimodal ImmuneAtlas; immune language models, antigen-presentation models and TME world models; an AI Scientist loop connecting hypothesis generation, simulation, robotic wet-lab testing and model updating; and generative immunotherapy plus the Second Me digital immune twin.
The evidence needs to be stratified. The strongest layer is adjacent technology: scGPT, Evo, virtual-cell work, IgLM, HLAPollo, LUMI-lab, self-driving laboratories and immunotherapy-response prediction models show that AI-for-biology components are emerging. The middle layer is OpenIO’s set of testable commitments: data standards, open benchmarks, open-source biologics and federated learning nodes. The weakest layer is the visionary one: whether immune scaling laws exist, whether 10^8-10^9 cells create transferable capability, whether Generative Yield can rise from below 1%, and whether first-in-human fully AI-designed biologics in 2027 or digital twin reports in 2028 can land all require future evidence.
Do not misread this in two ways. First, this is not proof that a new therapy has already been designed and validated by AI. Second, the Second Me digital immune twin is not a clinical standard tool. The authors explicitly frame the proposed timelines as aspirational goals rather than definitive predictions.
The leverage is shared infrastructure; the bottleneck is validation cost
OpenIO’s most useful AI-boundary lesson is that AI-native immunotherapy is not only about models. The leverage is shared data, shared benchmarks, shared reagents and closed-loop laboratories. Immunotherapy is too complex for every group to use incompatible data, reagents, metrics and validation protocols. Without shared infrastructure, foundation models can easily learn batch effects, cohort bias or experimental noise.
The bottleneck is equally clear: immune data is not text. Text tokens can be copied at scale. Immune data is shaped by sample handling, antibody batches, sequencing platforms, tissue origin, treatment timing, ancestry and sex composition. An in silico treatment suggestion does not mean the model can predict cytokine storm, T cell exhaustion, on-target/off-tumor toxicity or long-term survival.
This reinforces a broader rule for AI in biomedicine: the closer a task is to repeatable, low-cost and objectively scored validation, the faster AI can land; the closer it is to clinical decision-making, toxicity, accountability and long-horizon endpoints, the more stringent human validation must be.
Read it critically: vision, incentives and open promises
The first red flag is that vision can outrun evidence. OpenIO’s picture is coherent, but many core modules are still planned or supported by adjacent examples. A roadmap should not be treated as a completed platform. The Second Me digital twin and autonomous immunotherapy laboratory especially need prospective external validation and real clinical endpoints.
The second red flag is incentives. The declaration notes that one author is an employee of ByteDance Seed and another is the founder of Neolife AI. This does not invalidate the paper, but it means readers should treat it as a Commentary with ecosystem-building intent, not as a neutral systematic review.
The third red flag is whether open promises become usable assets. The paper says OpenIO will release patent-free immunological assets, open antibody sequences, diagnostic antibodies, standardized protocols, benchmarks and models. Without downloadable resources, licenses, versioning, external replication and failed-case records, open-source immunotherapy remains a slogan.
The fourth red flag is data governance. Federated learning can help with privacy, but it does not automatically solve cohort bias, assay drift, cross-hospital standardization or underrepresentation of specific populations. The reliability of immune foundation models ultimately depends on whether the data can be standardized, audited and updated.
The fifth red flag is clinical responsibility. If a digital twin participates in treatment selection and is wrong, who is accountable: the model developer, the hospital, the physician, the reagent provider or the data contributor? Without answers, AI clinical simulation remains hard to deploy beyond research settings.
What this implies for AI application boundaries
For investment or collaboration judgment, OpenIO offers a checklist. Does the project have a real multicenter data network? Standardized samples and reagents? Open benchmarks? A wet-lab loop? Failed data? Clinical endpoints and a regulatory path? If a company only talks about foundation models or digital twins without that base, commercial maturity is low.
For research tracking, I would follow three things: whether OpenIO releases usable data, models, benchmarks and experimental assets on schedule; whether immune scaling laws can be validated in controlled experiments; and whether Second Me-like digital immune twins can first prove value in lower-risk tasks such as patient stratification, trial design or toxicity-risk ranking rather than direct treatment guidance.
Two open questions matter. Does the immune system really contain engineerable scaling laws? And can AI-generated immunotherapy candidates shift validation cost away from clinical trial-and-error toward cheaper, objective and repeatable experimental loops?
Yang’s signal rating: Medium
Axis one, perspective value: High. Reason: OpenIO places the required data, models, experimental loops, open ecosystem and clinical simulation layer for AI-native immunotherapy on one map, making it useful for field-level judgment.
Axis two, field maturity: Medium-Low. Reason: adjacent technologies exist, but OpenIO itself remains mostly a roadmap. The expensive pieces are data standardization, experimental replication, first-in-human validation, clinical endpoints and accountability.
One-sentence summary: OpenIO is most useful because it shows what AI immunotherapy still needs to build; it is not yet evidence that AI-native immunotherapy is deployable.