SEED AI | CVSP-AIE:AI 筛库快在排序,慢在真实命中 SEED AI | CVSP-AIE makes AI screening faster at ranking, not at proving hits AI-assisted · reviewed
Huanxiang Liu、Tingjun Hou 和 Yu Kang 团队近期在 Nature Protocols 发表 CVSP-AIE(Comprehensive VS Platform with AI Engine)协议,把 KarmaDock、CarsiDock 和 RTMScore 三个 AI docking/scoring 模型封装成网页服务器和本地软件包。这篇文章值得读,不是因为它证明了某个新药已经被 AI 发现,而是因为它展示了 AI 在结构基础虚拟筛选中最实际的落点:把巨大化合物库先压缩成可实验验证的候选排序。
为什么结构基础筛库适合 AI 介入
这篇论文面对的瓶颈不是“有没有更多化合物”,而是命中发现早期同时卡在搜索空间、计算成本和工具门槛上。湿实验筛选能给直接证据,但成本高、覆盖化学空间有限;传统结构基础 docking 可以扩大搜索范围,却在速度、构象合理性、scoring 可靠性和部署复杂度之间反复取舍。
AI 介入的主因是搜索空间太大,次因是预测建模难、实验验证慢。价值链位置很清楚:它处在 design / screening 到 preclinical hit validation 之前,负责把 compound library 中的大量分子快速排序,而不是替代后续生化 assay、细胞实验或 ADMET 验证。
真正的新意是把三个 AI 模型变成可执行筛选流程
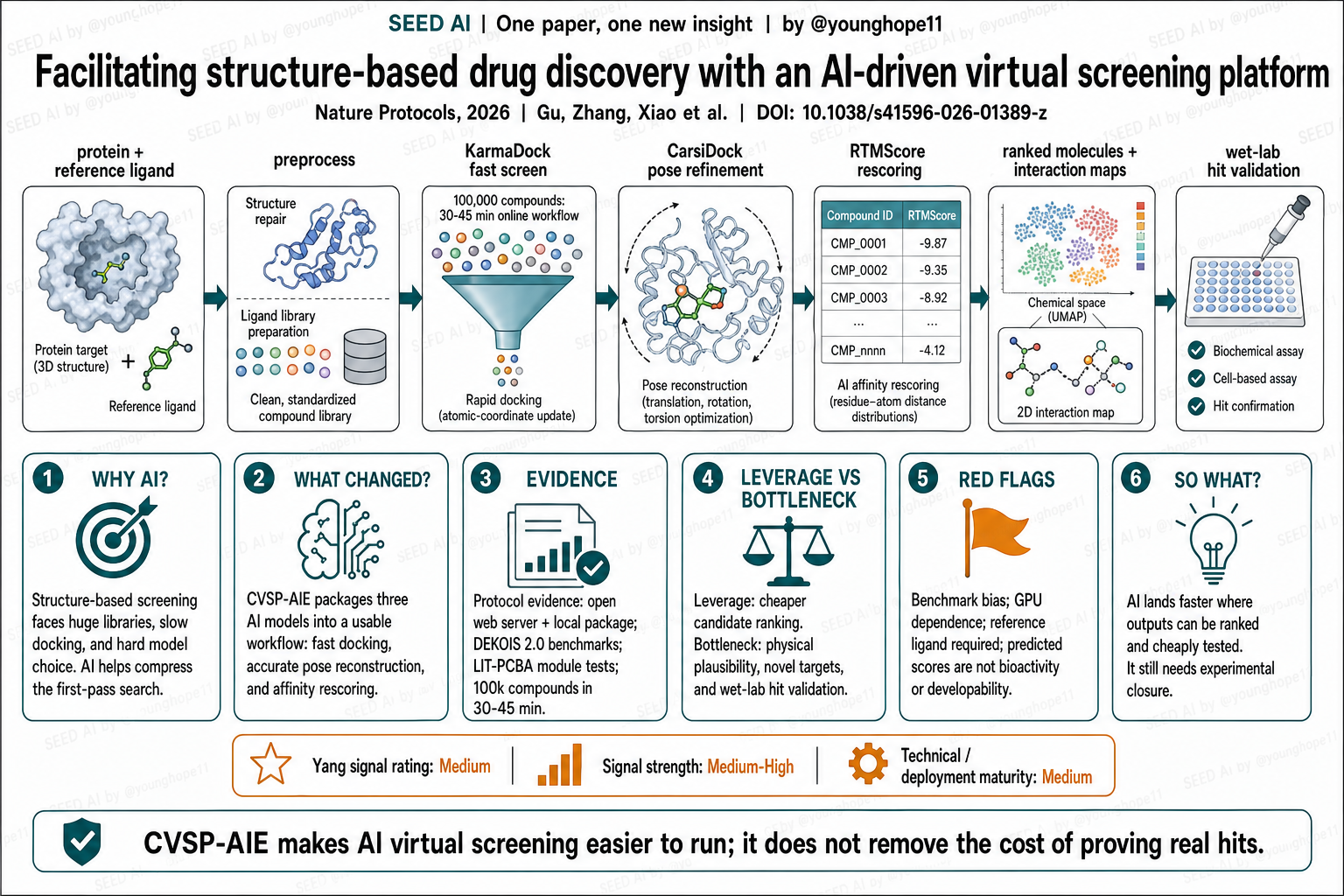
CVSP-AIE 改变的是虚拟筛选的工作流封装。它不是只发布一个模型,而是把三个功能不同的模型串起来:KarmaDock 用直接更新原子坐标的方式做高速 docking;CarsiDock 预测蛋白-配体距离矩阵,并用平移、旋转和 torsion-guided 优化重建更可信的结合姿势;RTMScore 用 residue-atom 距离分布做 affinity rescoring。
这三者的组合形成了 hierarchical VS:先用 KarmaDock 快速扫完整库,再把 top N 候选交给 CarsiDock 和 RTMScore 做更精细的 pose 与 score。网页端让实验人员通过上传 protein 和 reference ligand 启动流程;本地包则允许更大规模任务在用户自己的 GPU 环境中运行。
所以它真正改变的是“AI docking 如何被非算法团队使用”。模型本身的性能来自前序论文,这篇 Protocol 的贡献是把它们组织成可复现、可部署、可排错的筛选系统。
证据强在可执行性,弱在真实命中闭环
这篇最强的证据形态是协议可执行性加既有 benchmark。CVSP-AIE 提供网页服务器、本地 Docker/PyPI 包和 MIT license 源码;论文给出完整的 preprocessing、HierarchicalVS、HeVS、HpVS、HpRS、CvPL 操作步骤,并在 LIT-PCBA 的 10 个靶点(ALDH1、ESR1_ant、FEN1、GBA、KAT2A、MAPK1、MTORC1、PKM2、TP53、VDR)上测试各模块以总结 troubleshooting。
性能证据主要来自作者之前发表的模型和 benchmark。DEKOIS 2.0 上,KarmaDock 的 EF_1% 为 15.833,CarsiDock 为 18.910,Glide_RTMScore 为 18.530;KarmaDock 单次 docking/scoring 平均 0.017 s,远快于 CarsiDock 的 1.726 s 和传统 Glide SP 的 23.798 s。协议端给出的时间也具体:网页 HierarchicalVS 对 100,000 个 compounds 做快速 docking,并对 top 1,000 做精细 docking/rescoring,约 34-45 min;本地包处理 1,000,000 个 compounds 并对 top 100,000 精细处理约 16-20 h。
别误读第一点:这些是计算排序、benchmark 和流程测试,不是湿实验 hit rate。别误读第二点:benchmark 强不等于可落地命中,因为虚拟筛选最终要看真实 assay、构象合理性、新靶点泛化、选择性、可合成性和成药性。
最重要的一点:杠杆在排序压缩,卡点在实验闭环
CVSP-AIE 对 AI 应用边界的核心判断是:AI 在虚拟筛选里最先产生价值的地方,是便宜地压缩候选分母。它能把“百万级化合物库里先看谁”变成一个自动化、可视化、可下载的排序流程,尤其适合把实验验证资源集中到更小的候选集合。
但卡点没有消失。AI score 不是 binding evidence,dock pose 不是生化活性,chemical space visualization 也不是 developability。论文自己也列出关键限制:KarmaDock 生成的多数分子姿势未通过 PB-valid 检测;AI 方法对新靶点和新配体可能显著掉性能;在线服务器有排队和规模限制;平台需要 reference ligand 来定义 binding pocket。
这再次说明验证成本的边界:当输出只是“排序列表”时,AI 可以很快;当问题变成“这个分子是否真实结合、是否选择性好、是否能成为 lead”时,速度仍由湿实验和药化闭环决定。
批判性阅读:不要把虚拟筛选分数当成真实药效
第一条红旗是 benchmark bias。论文明确提醒,VS benchmark 可能有设计偏差,让 AI 模型通过记忆数据分布获得高分,而不是学到蛋白-配体相互作用原则。尤其在 novel targets 或 novel chemical entities 上,模型性能可能明显下降。
第二条红旗是物理合理性。KarmaDock 极快,但直接更新坐标、不显式引入键连接信息,导致多数输出 pose 难以通过 PB-valid 检测;CarsiDock 的设计改善了构象合理性,但相比 physics-based docking 仍有差距。
第三条红旗是硬件公平性。表格里的 AI 工具用 GPU 加速,传统 docking 的时间多来自单线程 CPU 计算。真实项目中,如果传统工具使用多核并行,速度差距和成本结构需要重新算。
第四条红旗是 workflow 依赖。平台要求 receptor 有明确 binding site,并需要 reference ligand 定义 pocket;如果只有 apo protein,用户还要先用 AlphaFold 3、Boltz2 等工具建模复合物,错误会向后传递。
第五条红旗是结果解释。CVSP-AIE 输出的是 ranking、predicted scores、interaction maps 和 chemical-space plots。它们适合指导下一步实验,但不能直接被解释为 bioactivity、selectivity、toxicity 或 clinical potential。
对 AI 应用边界的启发
投资 / 合作判断上,这类平台的价值不在于宣称“AI 自动发现药物”,而在于是否真正降低 hit-finding 前半段的验证成本。值得看的不是漂亮网页,而是外部用户能否在不同靶点上稳定复现候选压缩,是否有失败案例、湿实验命中率、药化跟进和真实项目 ROI。
科研方向跟踪上,我会继续看三个方向:第一,AI docking/scoring 在 LIT-PCBA、DUD-E 之外的新 benchmark 和前瞻性项目表现;第二,物理约束、pose validity 和 affinity prediction 能否同时提高;第三,CVSP-AIE 这类平台能否接上自动化 wet-lab,把 predicted ranking 直接变成 hit-confirmation feedback。
待解问题有两个:AI virtual screening 能否在新靶点、新 scaffold 和真实湿实验中稳定提高 hit-to-validation rate?以及,平台输出的 top-ranked molecules 中有多少失败来自模型错误,多少失败来自蛋白构象、pocket 定义、化合物制备和 assay 条件?
Yang 的信号评级:Medium
轴一,信号强度:Medium-High。理由:CVSP-AIE 把已有 AI docking/scoring 模型变成了可运行、可部署、可排错的 Protocol,并给出具体 benchmark、时间成本和开放代码,对真实科研使用很有帮助。
轴二,技术/落地成熟度:Medium。理由:作为计算筛库工具,它已经相当接近可用;作为发现真实 hit/lead 的完整系统,它仍受 benchmark 偏差、pose validity、新靶点泛化、GPU 成本和湿实验闭环限制。
一句话总结:CVSP-AIE 说明 AI 虚拟筛选最先改变的是候选排序成本,而不是免除证明真实命中的实验成本。
The Huanxiang Liu, Tingjun Hou and Yu Kang teams recently published a Nature Protocols paper on CVSP-AIE, the Comprehensive VS Platform with AI Engine, which packages KarmaDock, CarsiDock and RTMScore into a web server and local software package. The paper is worth reading not because it proves that AI has already discovered a new drug, but because it shows a practical AI landing point in structure-based virtual screening: compress a large compound library into a smaller, experimentally testable candidate ranking.
Why structure-based screening invites AI
The bottleneck is not simply the existence of more compounds. Early hit discovery is constrained by search space, compute cost and tool usability. Wet-lab screening provides direct evidence, but it is expensive and covers limited chemical space. Traditional structure-based docking expands the search space, but it forces trade-offs among speed, pose plausibility, scoring reliability and deployment complexity.
The primary reason for AI intervention is that the search space is too large. Secondary reasons are difficult prediction and slow experimental validation. The value-chain position is before design/screening to preclinical hit validation: rank many molecules from a compound library faster, not replace biochemical assays, cell experiments or ADMET validation.
What changed is workflow packaging for three AI models
CVSP-AIE changes the workflow packaging of virtual screening. It does not only release one model. It connects three models with different roles: KarmaDock performs fast docking by directly updating atomic coordinates; CarsiDock predicts protein-ligand distance matrices and reconstructs more credible poses through translation, rotation and torsion-guided optimization; RTMScore uses residue-atom distance distributions for affinity rescoring.
Together, these models form hierarchical virtual screening. KarmaDock first scans the full library, and then the top N candidates move to CarsiDock and RTMScore for finer pose and score assessment. The web server lets experimental users start from a protein and reference ligand upload; the local package lets larger jobs run in the user’s own GPU environment.
The real contribution is therefore not another isolated AI model. It is making AI docking usable by non-algorithm teams through a reproducible, deployable and troubleshootable screening system.
The evidence is execution-ready, but not wet-lab closure
The strongest evidence shape is protocol executability plus prior benchmarks. CVSP-AIE provides a web server, a local Docker/PyPI package and MIT-licensed source code. The paper lays out preprocessing, HierarchicalVS, HeVS, HpVS, HpRS and CvPL procedures, and it evaluated the modules on 10 LIT-PCBA targets - ALDH1, ESR1_ant, FEN1, GBA, KAT2A, MAPK1, MTORC1, PKM2, TP53 and VDR - to support troubleshooting.
The performance evidence mainly comes from the authors’ earlier model and benchmark publications. On DEKOIS 2.0, KarmaDock reports EF_1% of 15.833, CarsiDock 18.910 and Glide_RTMScore 18.530. KarmaDock averages 0.017 s per docking/scoring event, far faster than CarsiDock at 1.726 s and Glide SP at 23.798 s. The protocol timing is also concrete: the web HierarchicalVS workflow handles 100,000 compounds with fast docking and refines the top 1,000 by precise docking and rescoring in about 34-45 min; the local package processes 1,000,000 compounds and refines the top 100,000 in about 16-20 h.
Do not misread this in two ways. First, these are computational rankings, benchmarks and workflow tests, not wet-lab hit rates. Second, benchmark strength does not equal deployable hits, because virtual screening ultimately depends on real assays, pose plausibility, novel-target generalization, selectivity, synthesizability and developability.
The leverage is ranking compression; the bottleneck is experimental closure
CVSP-AIE’s core AI-boundary lesson is that virtual screening first benefits from cheaper candidate-ranking. It turns the question “which molecules should we test first from a million-scale library?” into an automated, visual and downloadable ranking workflow. That is useful because it focuses experimental validation on a smaller candidate set.
But the bottleneck remains. An AI score is not binding evidence, a docked pose is not biochemical activity, and a chemical-space visualization is not developability. The paper itself lists important constraints: most KarmaDock-generated poses fail PB-valid detection; AI methods may perform much worse on novel targets and ligands; the online server has queue and scale limits; and the platform needs a reference ligand to define the binding pocket.
This fits the validation-cost rule: when the output is a ranking list, AI can move quickly; when the question becomes whether a molecule truly binds, is selective and can become a lead, the speed is still set by wet-lab and medicinal-chemistry closure.
Read it critically: do not treat virtual-screening scores as real efficacy
The first red flag is benchmark bias. The paper explicitly notes that virtual-screening benchmarks can contain design biases, allowing AI models to score well by memorizing data distributions rather than learning general principles of protein-ligand interaction. Performance can decline on novel targets or novel chemical entities.
The second red flag is physical plausibility. KarmaDock is extremely fast, but it directly updates coordinates without explicitly incorporating bond information, causing many poses to fail PB-valid detection. CarsiDock improves pose rationality, but a gap remains versus physics-based docking.
The third red flag is hardware fairness. The reported AI timings use GPU acceleration, whereas traditional docking timings are largely based on single-threaded CPU calculations. In real campaigns, if traditional tools use multicore parallelization, the speed and cost comparison needs to be recalculated.
The fourth red flag is workflow dependence. The platform requires a receptor with a defined binding site and a reference ligand to define the pocket. If only an apo protein is available, users need tools such as AlphaFold 3 or Boltz2 to model the complex first, and errors can propagate downstream.
The fifth red flag is result interpretation. CVSP-AIE outputs rankings, predicted scores, interaction maps and chemical-space plots. These are useful for guiding the next experiment, but they cannot be read directly as bioactivity, selectivity, toxicity or clinical potential.
What this implies for AI application boundaries
For investment or collaboration judgment, the value of this type of platform is not the claim that “AI automatically discovers drugs.” It is whether the platform lowers validation cost in the first half of hit finding. The important questions are whether external users can reproducibly compress candidates across targets, whether failures are visible, and whether wet-lab hit rates, medicinal-chemistry follow-up and project ROI improve.
For research tracking, I would follow three directions: AI docking and scoring on newer benchmarks and prospective projects beyond LIT-PCBA and DUD-E; whether physical constraints, pose validity and affinity prediction can improve together; and whether platforms like CVSP-AIE can connect to automated wet-lab systems so predicted rankings become hit-confirmation feedback.
Two open questions matter. Can AI virtual screening reliably improve hit-to-validation rate for new targets, new scaffolds and real assays? And among top-ranked molecules that fail, how much failure comes from model error versus protein conformation, pocket definition, compound preparation or assay conditions?
Yang’s signal rating: Medium
Axis one, signal strength: Medium-High. Reason: CVSP-AIE turns existing AI docking and scoring models into an executable, deployable and troubleshootable protocol, with concrete benchmarks, timing estimates and open code.
Axis two, technical / deployment maturity: Medium. Reason: as a computational screening tool, it is close to usable. As a complete real-hit or lead-discovery system, it remains constrained by benchmark bias, pose validity, novel-target generalization, GPU cost and wet-lab closure.
One-sentence summary: CVSP-AIE shows that AI virtual screening first changes the cost of candidate ranking, not the experimental cost of proving real hits.